 by
by In this post, we explain basic principles of feedback control method. The video accompanying this post is given below.
In our previous post (see this post and this post), we have introduced a model of a mass-spring-damper system. This system will be used to motivate and to explain basic principles of feedback control. We are using this system model since it can be used to mathematically model a number of mechanical, electrical, chemical, technological, and physical systems. The sketch of the system is given in the figure below.
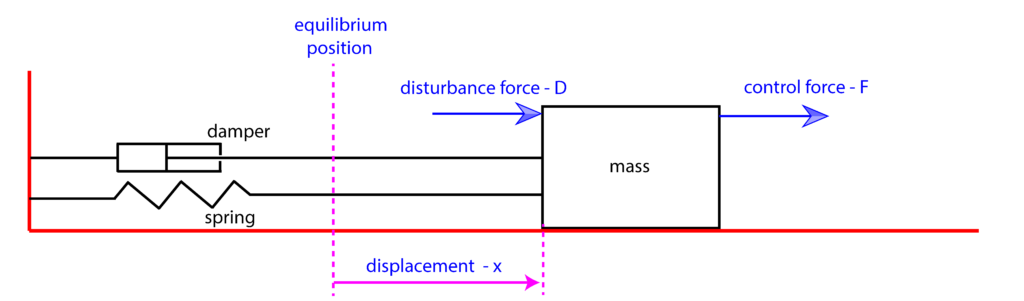
The goal of the control algorithm is to move (steer) the object of the mass  to the desired position, which is denoted by
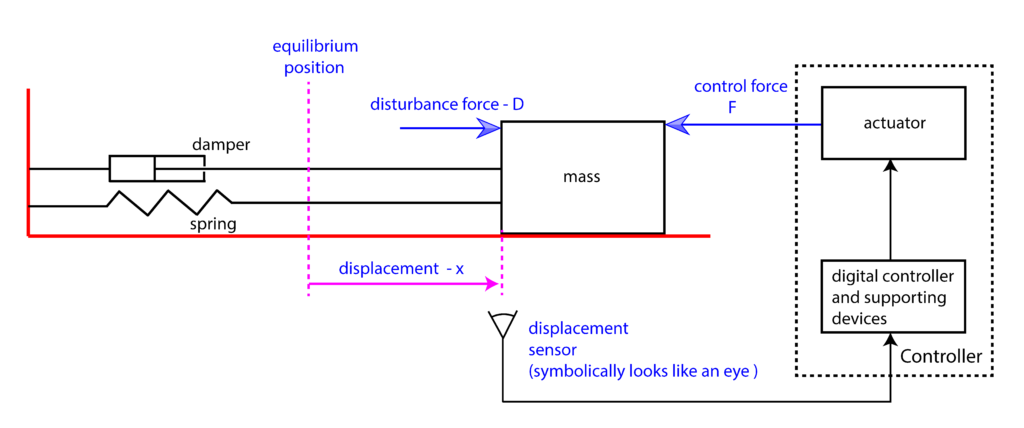
to the desired position, which is denoted by  (reference position). We assume that there is a sensor measuring the object displacement. On the basis of the sensor measurement, and on the basis of the reference (desired) object position, we can compute the control error
(reference position). We assume that there is a sensor measuring the object displacement. On the basis of the sensor measurement, and on the basis of the reference (desired) object position, we can compute the control error
(1) 
where
 is the displacement. The controller takes the control error as an input, and on the basis of this control error, it generates the control force
is the displacement. The controller takes the control error as an input, and on the basis of this control error, it generates the control force  . Since the main purpose of this lecture is to introduce basic principles of feedback control, and in order not to blur the main ideas with additional mathematical perplexities, in this post, we assume a simple form of the control algorithm that is mathematically represented by the following equation
. Since the main purpose of this lecture is to introduce basic principles of feedback control, and in order not to blur the main ideas with additional mathematical perplexities, in this post, we assume a simple form of the control algorithm that is mathematically represented by the following equation (2) 
where
 is a control parameter that we need to determine. Since the control force is directly proportional to the control error, this type of controller is referred to as the proportional feedback controller. This feedback control approach as well as other feedback control schemes can be illustrated by a diagram shown in the figure below.
is a control parameter that we need to determine. Since the control force is directly proportional to the control error, this type of controller is referred to as the proportional feedback controller. This feedback control approach as well as other feedback control schemes can be illustrated by a diagram shown in the figure below.
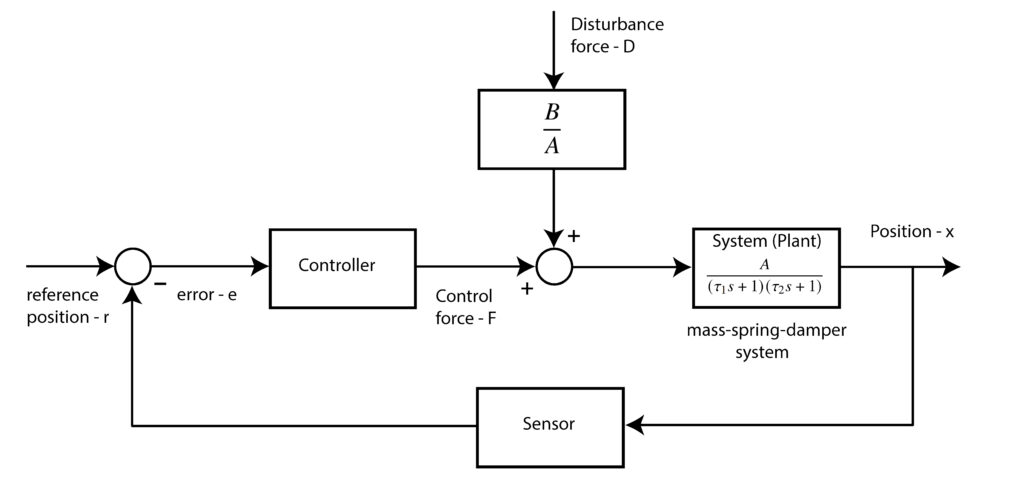
The system transfer function model that is explained in the previous post, has the following form.
(3) 
where
 and
and  are transfer functions defined as follows
are transfer functions defined as follows (4) 
and where
 and
and  are the Laplace transforms of the control force and disturbance force
are the Laplace transforms of the control force and disturbance force  ,
,  is the Laplace transform of the displacement , and
is the Laplace transform of the displacement , and  and
and  are system parameters.
are system parameters.
The feedback control approach can be graphically represented by the following block diagram.
Let us now investigate the effect of this controller structure on the overall system performance. First, we assume that the reference signal and the disturbance force are constants, and that they are denoted by
(5) 
That is, we assume that the control objective is to displace the object to the position
 and to keep the object at that position. Next, we take Laplace transforms of the equations (2), (5), and (14):
and to keep the object at that position. Next, we take Laplace transforms of the equations (2), (5), and (14): (6) 
By substituting (6) in (3), we obtain
(7) 
and the final expression
(8) 
Let us assume that the controller
 is selected such that the poles of the transfer function
is selected such that the poles of the transfer function (9) 
are in the left-half od the s-plane. That is, we assume that the equilibrium point of the system is asymptotically stable. Under this assumption, we can apply the final value theorem. The final value theorem states that if the poles of the expression
 are in the left part of the s-plane, then we have
are in the left part of the s-plane, then we have (10) 
where
 is the steady-state object position. By applying this theorem to (8) we obtain
is the steady-state object position. By applying this theorem to (8) we obtain (11) 
Let us now evaluate these limit values. From (4), we obtain
(12) 
Substituting these expressions in the last equation of (11), we obtain
(13) 
Let us now compute the steady-state error:
(14) 
or
(15) 
On the other hand, from our previous post, it follows that the open-loop steady-state position and error are given by:
(16) 
(17) 
This analysis enables us to draw the following conclusions.
- Benefits of high feedback gain. From (13) and (15) we can observe that if
 and
and  , then
, then (18)

This implies that(19)

That is if the value of the product is high, then, we achieve:
is high, then, we achieve:
a) Small steady-state error. This means that our object will practically reach the desired destination.
b) Good disturbance rejection.
The number is the gain of the feedback loop. This can be seen in Figure 3. Consequently, this control approach is called the high-feedback gain control approach. As we will see in our next post, another benefit of increasing the feedback gain is that we can in some sense increase the system robustness. However, for certain classes of systems, high-gain feedback can destabilize the control system! This will be explained in one of our future posts (links will be provided later). In practice, we often need to perform loop shaping to achieve optimal values of controller parameters. - If we compare the open-loop and closed-loop steady-state displacements and errors, we conclude that with feedback control we are able to attenuate the effect of disturbances on our system. Furthermore, we will see in our future posts that feedback control is more robust than the open-loop control.
There are also other benefits and trade-offs in feedback control. These properties of feedback control will be explained in our next posts.