 by
by In this post, we introduce an open-loop control approach. We also introduce MATLAB codes that can be used to simulate the dynamics of a system that is controlled using the open-loop control method. A video accompanying this post is given below.
We can use open-loop control when we have perfect knowledge about the system that we want to control, and we do not expect that some unpredictable events or disturbances will affect the system during its operation. Since it does not rely upon feedback information that is collected by sensors, open-loop control is simple and cost-effective.
In our previous post, we have explained how to derive a transfer function model of the mass-spring-damper system shown in the figure below. In this post, we explain how to design an open-loop controller for such a system.
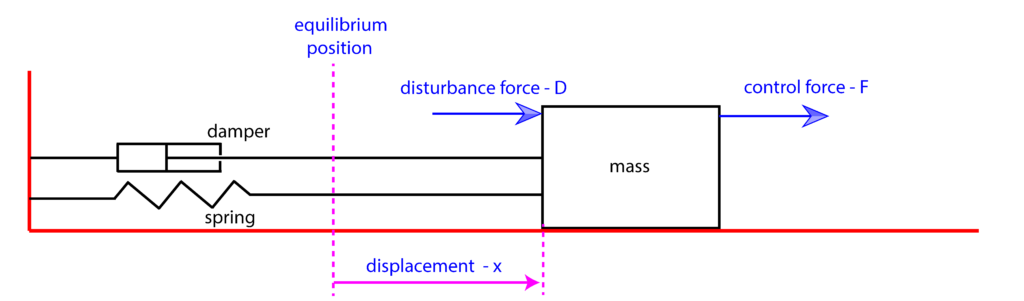
The transfer function model has the following form:
(1) 
where
 , and
, and  are Laplace transforms of the position
are Laplace transforms of the position  , control force
, control force  , and disturbance force
, and disturbance force  , and
, and  , and
, and  are constants (for more details see our previous post). For our MATLAB simulations (at the end of this post), we define:
are constants (for more details see our previous post). For our MATLAB simulations (at the end of this post), we define:
(2) 
where  is the transfer function from the control force to the displacement, and
is the transfer function from the control force to the displacement, and  is the transfer function from the disturbance force to the displacement. A block diagram of the system is shown below.
is the transfer function from the disturbance force to the displacement. A block diagram of the system is shown below.
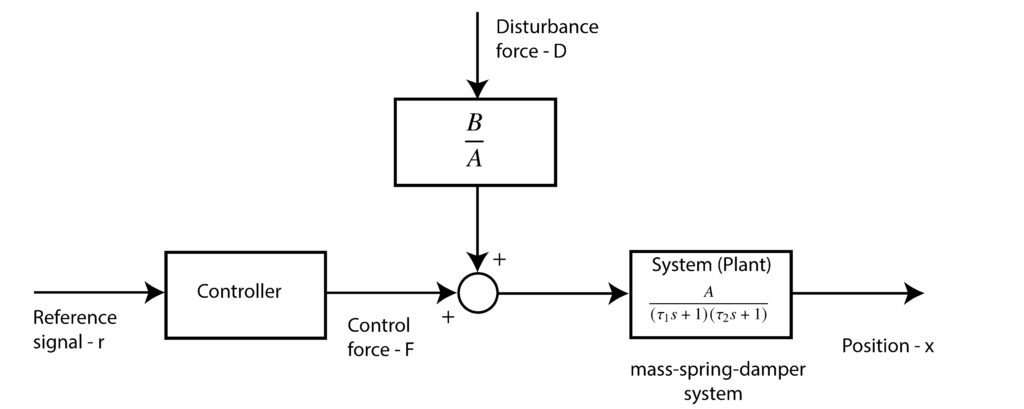
We have deliberately reformulated the system description in order to emphasize different system parts. We have also introduced a controller. The purpose of the controller is to generate the control force  such that the system’s position
such that the system’s position  (displacement) becomes equal to a reference signal
(displacement) becomes equal to a reference signal  that represents a desired position of the mass. Our goal is to design such a controller.
that represents a desired position of the mass. Our goal is to design such a controller.
For the time being, we are going to exclude the disturbance force, since in practice we often do not have a priori knowledge about disturbances acting on the system. Consequently, the system’s model has the following form
(3) 
and the controller will have the following form
(4) 
where
 is an open-loop control gain. Let us assume that the control objective is to keep
is an open-loop control gain. Let us assume that the control objective is to keep  , for
, for  . Substituting this equation in (4), we obtain
. Substituting this equation in (4), we obtain (5) 
Applying the Laplace tranform to (5), we obtain
(6) 
Substituting (6) in (3), we obtain
(7) 
Next, we recall the final value theorem. The final value theorem states that if all the poles of
 are in the left half of the s-plane, then
are in the left half of the s-plane, then (8) 
Since in our case, the poles of
 are in the left half of the s-plane (the mass-spring-damper system is asymptotically stable), from (7) and the final value theorem, we obtain
are in the left half of the s-plane (the mass-spring-damper system is asymptotically stable), from (7) and the final value theorem, we obtain (9) 
where
 is the steady-state position of the mass. From the last equation, we obtain
is the steady-state position of the mass. From the last equation, we obtain (10) 
Our goal is to make
 . From (10), we see that this achieved when
. From (10), we see that this achieved when (11) 
That is, when
 , then . On the other hand, let us see what is the physical meaning of the parameter
, then . On the other hand, let us see what is the physical meaning of the parameter  . Consider a unit step control force applied to the system
. Consider a unit step control force applied to the system (12) 
Then, we have
(13) 
In this case, the steady state system response is computed as follows
(14) 
That is, the parameter
is the steady-state gain of the open-loop system. Consequently, the open-loop controller gain  should be equal to the inverse of the system open-loop gain. In some sense, the open-loop controller inverts the system. This is also true for more complex open loop dynamic controllers.
should be equal to the inverse of the system open-loop gain. In some sense, the open-loop controller inverts the system. This is also true for more complex open loop dynamic controllers.
Let us now numerically test this control approach.
First, we define the transfer function using the approach explained in this post.
clear, pack, clc
% define system parameters
% mass
m=10
% damping
kd=1
% spring constant
ks=100
% control force constant
b=5
% disturbance constant
c=0.1
% Defining transfer functions
% compute the poles
s1=(-(kd/m)+sqrt( (kd/m)^2 -4*(ks/m) ))/2
s2=(-(kd/m)-sqrt( (kd/m)^2 -4*(ks/m) ))/2
tau1= 1/(-s1);
tau2= 1/(-s2);
A=b/ks;
B=c/ks;
s = tf('s');
W1=A/((tau1*s+1)*(tau2*s+1))
W2=B/((tau1*s+1)*(tau2*s+1))
Next, we simulate the system response when the control gain is computed on the basis of the perfect knowledge of the system steady-state gain . We assume that the value of the reference signal is 10. That is, the desired mass displacement is 10, and the controller should ensure that the mass reaches this value in the steady-state. The MATLAB code is given below
% this is the response of the system that is not controlled
desired_position=10;
time_vector=0:0.1:100;
input_signal=desired_position*ones(size(time_vector));
X = lsim(W1,input_signal,time_vector);
% now, let us add an open loop controller
K=1/A
W1_controlled=W1*K
X_controlled = lsim(W1_controlled,input_signal,time_vector)
figure(1)
% uncontrolled system
plot(time_vector,X,'r')
hold on
% controlled system
plot(time_vector,X_controlled,'k')
The results are shown in the graph below.
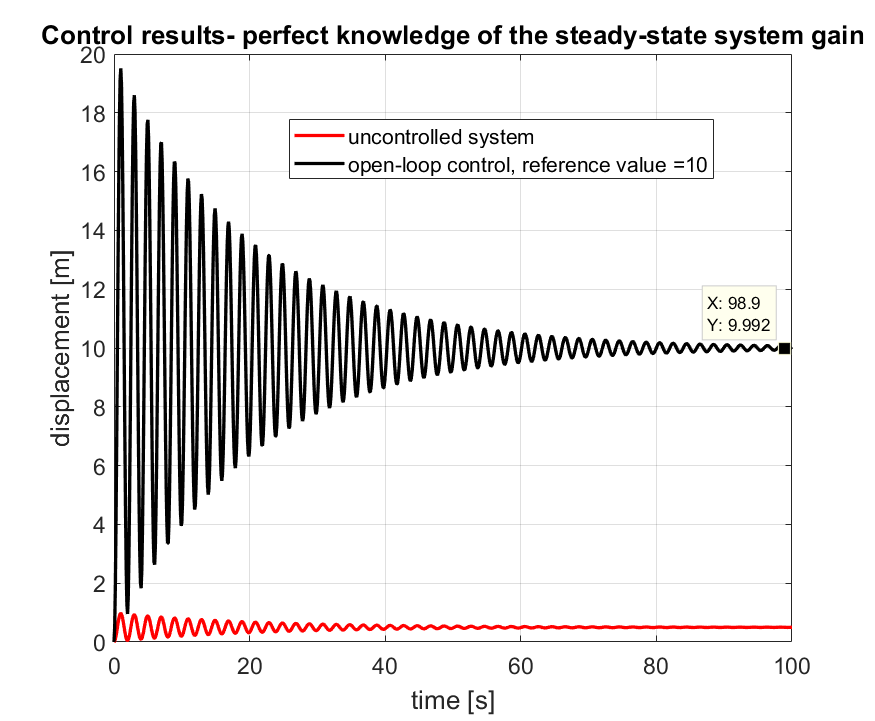
Obviously, there are at least two drawbacks of the open-loop control approach. The first drawback that in practice we often do not know the precise system model. In our case, we might not know accurately, the steady-state system gain. The effect of the lack of precise knowledge of the system gain on the control system performance is simulated using the code given below.
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% drawbacks of the open loop control approach
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 1. we do not know the open loop gain A accuratelly
% for example we assume that the value of A that we know is equal to 0.8*A
K2=1/(0.8*A)
W1_controlled2=W1*K2
X_controlled2 = lsim(W1_controlled2,input_signal,time_vector)
figure(2)
% uncontrolled system
plot(time_vector,X,'r')
hold on
% controlled system - accurate knowledge of A
plot(time_vector,X_controlled,'k')
% controlled system - inaccurate knowledge of A
plot(time_vector,X_controlled2,'b')
The control results are presented in the graph below.
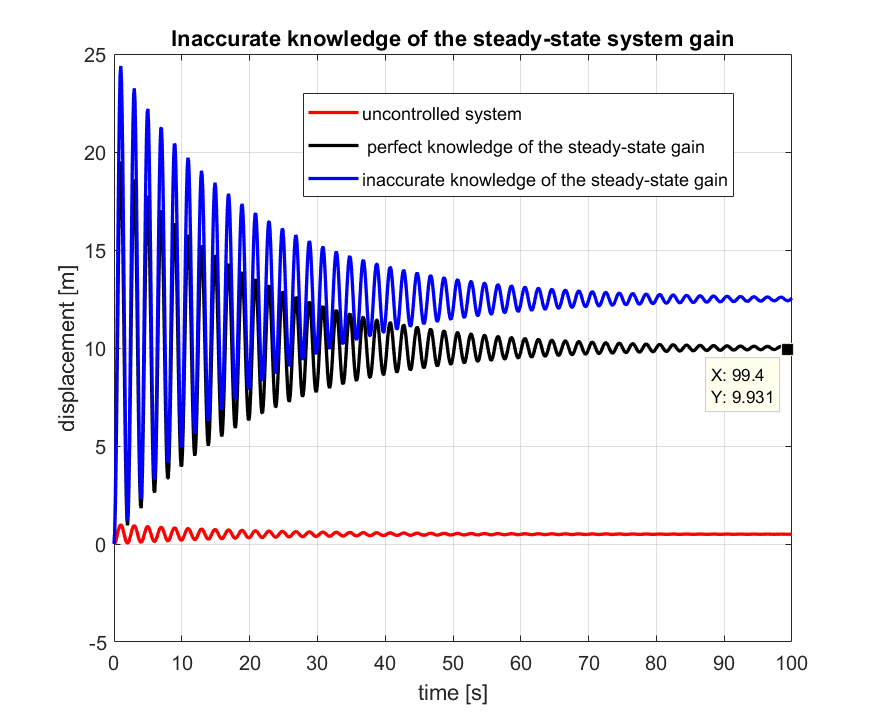
Also, another drawback of the open-loop control is that the controller completely blind with respect to the disturbance that can act on the system. The disturbances can severely deteriorate the system performance. The code below illustrates the effect of disturbances.
% 2. disturbance is acting on the system
% compute the response to the disturbance force
time_vector=0:0.1:100;
disturbance_signal=1000*ones(size(time_vector));
X_disturbance = lsim(W2,disturbance_signal,time_vector);
% system is linear- so we can do this:
X_with_disturbance= X_controlled + X_disturbance;
figure(3)
% uncontrolled system
plot(time_vector,X,'r')
hold on
% controlled system - accurate knowledge of A - no disturbance
plot(time_vector,X_controlled,'k')
% controlled system - accurate knowledge of A - with disturbance
plot(time_vector,X_with_disturbance,'b')
The results are shown in figure below.
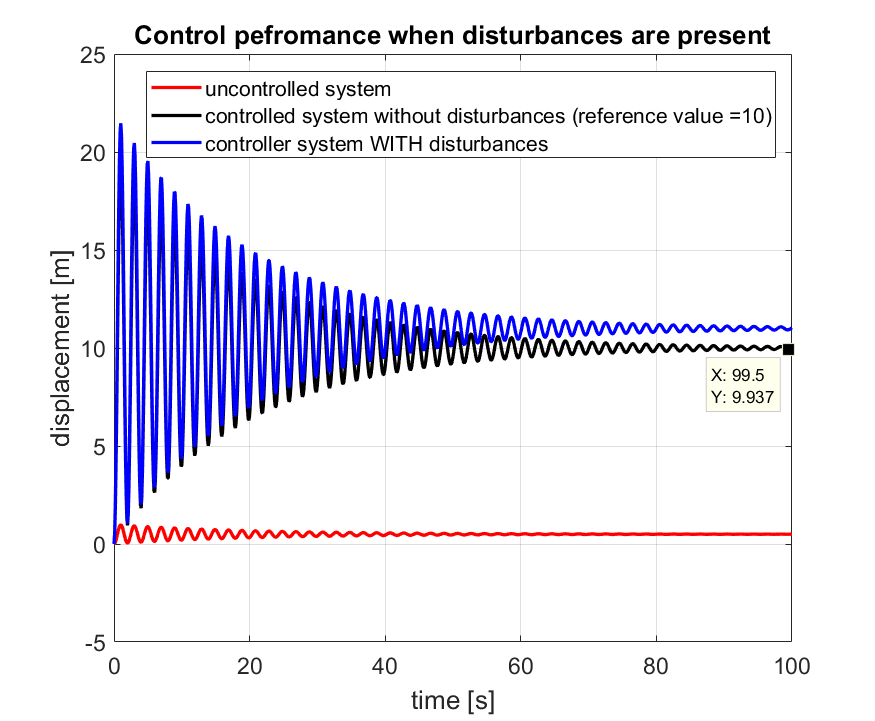
To summarize: open-loop control approach is useful when the system dynamics is known accurately and where there are no unmodeled disturbances acting on the system. The open-loop control approach presented in this post is based on the knowledge of the system steady-state gain. Consequently, we were not able to influence the transient response of the system using this approach. However, there are more advanced open-loop control approaches that can influence the system transient response.