 by
by
In this control system tutorial, we explain how to develop a controller by using a pole-placement method. The controller includes an integral control action to eliminate steady-state errors. We explain how to model and simulate this controller in Simulink and MATLAB. The YouTube tutorial is given below. In our next tutorial, whose link is given here, we explain how to model the Linear Quadratic Regulator (LQR) controller in Simulink.
As a test case, we consider the mass-spring-damper system shown in the figure below.
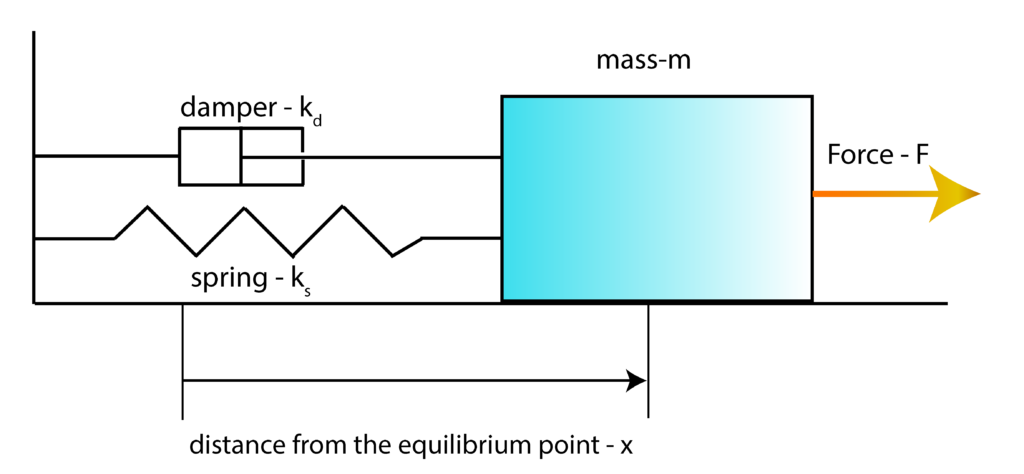
This model is thoroughly explained in our previous tutorial which can be found here. The distance from the equilibrium point is denoted by  . The spring and damper constants are denoted by
. The spring and damper constants are denoted by  and
and  . The force is denoted by
. The force is denoted by  and the mass of the object is denoted by
and the mass of the object is denoted by  . In our previous tutorial, we derived the state-space model of the system. The state-space variables are
. In our previous tutorial, we derived the state-space model of the system. The state-space variables are
(1) 
The resulting state-space model has the following form:
(2) 
where
(3) 
Our goal is to design a controller that will make the output  of the system (2) track a constant reference signal. Let the reference signal be denoted by
of the system (2) track a constant reference signal. Let the reference signal be denoted by  . The reference signal is a desired output determined by the user. Let the control error (also called the tracking error), be denoted by
. The reference signal is a desired output determined by the user. Let the control error (also called the tracking error), be denoted by
(4) 
Then, the goal of the controller is to decrease the control error as close as possible to zero.
The basic controller based on pole placement or Linear Quadratic Regulator (LQR) can be used to steer the system to the zero equilibrium point. That is, these controllers can be used to steer the system’s state to zero state  . However, in the most general case, they will not ensure that the error (4) will converge to zero. To ensure that the error converges to zero for a constant reference signal, we need to add an integrator to our controller.
. However, in the most general case, they will not ensure that the error (4) will converge to zero. To ensure that the error converges to zero for a constant reference signal, we need to add an integrator to our controller.
We add an integrator by augmenting our original state-space model, with the state of the integral controller. Let us introduce a new variable  that is an integral of the control error. That is,
that is an integral of the control error. That is,
(5) 
By taking the first derivative of (5), we obtain
(6) 
By substituting the output equation of the state-space model (2) in (6), we obtain
(7) 
By combining the state equation of the model (2) with the integral controller (7), we obtain
(8) 
The last two equations can be written in the compact form
(9) 
The last equation can be written compactly as follows
(10) 
where
(11) 
In this tutorial, we assume that the state vector of the augmented system  is known. In our next tutorial, we will relax this assumption by introducing a state observer. Consequently, we can design a state-feedback controller that will place the poles of the closed-loop system in desired locations in the complex plane. For example, to place the poles at the desired locations we can use the MATLAB function “place()”. This will be explained later in the tutorial. The pole placement method designs a feedback control law:
is known. In our next tutorial, we will relax this assumption by introducing a state observer. Consequently, we can design a state-feedback controller that will place the poles of the closed-loop system in desired locations in the complex plane. For example, to place the poles at the desired locations we can use the MATLAB function “place()”. This will be explained later in the tutorial. The pole placement method designs a feedback control law:
(12) 
By partitioning  as follows
as follows
(13) 
and by using the definition of given in (11), we obtain
(14) 
By using (5), the last equation can be written as follows
(15) 
We can clearly observe that the controller explicitly takes into account the integral of the control error. To develop a Simulink model and simulate it, we need to create a block diagram of the system and the controller. The block diagram is given below.
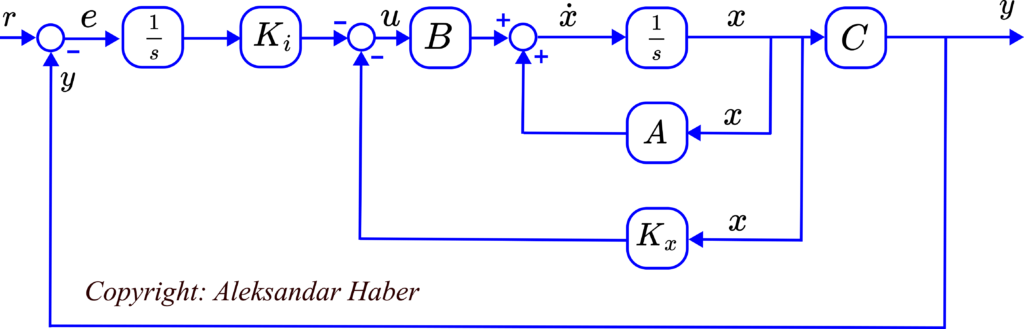
The MATLAB code is given below.
ks=1
kd=0.1
m=10
A=[0 1; -ks/m -kd/m];
B=[0; 1/m];
C=[1 0]
D=[0]
% compute the open loop poles
openLoopPoles=eig(A)
% form the augmented system
Aa=[A [0; 0]; -C 0]
Ba=[B;0]
% set the desired closed-loop pole locations
desiredClosedPoles=[-2+0.2i; -2-0.2i;-3]
% use the place command to place the closed loop poles at the desired
% locations
K=place(Aa,Ba,desiredClosedPoles)
% check the closed loop poles
eig(Aa-Ba*K)
% extract feedback matrices
Kx=K(:,1:2)
Ki=K(3)
This code will calculate the feedback control matrix that will place the poles at the desired locations specified by the vector “desiredClosedPoles”. Then, from the calculated matrix, we can extract  and
and  . Before creating the Simulink model, it is important to run this MATLAB script such that all the necessary variables are in the MATLAB workspace and such that the Simulink model can access these variables. The Simulink modeling and simulation is explained in the YouTube tutorial video at the top of this page.
. Before creating the Simulink model, it is important to run this MATLAB script such that all the necessary variables are in the MATLAB workspace and such that the Simulink model can access these variables. The Simulink modeling and simulation is explained in the YouTube tutorial video at the top of this page.