 by
by
In this tutorial, we explain how to install and use the OpenAI Gym Python library for simulating and visualizing the performance of reinforcement learning algorithms. The YouTube video accompanying this post is given below.
First, we install the OpenAI Gym library. This can be performed by opening your terminal or the Anaconda terminal and by typing
pip install gym
pip install gym[toy_text]
The next step is to open the Python editor, and write these code lines:
import gym
env=gym.make("FrozenLake-v1", render_mode="human")
env.reset()
# render the environment
env.render()
These code lines will import the OpenAI Gym library (import gym) , create the Frozen Lake environment (env=gym.make(“FrozenLake-v1″, render_mode=”human”)), reset the environment (env.reset()), and render the environment (env.render()). The result is the environment shown below
SFFF
FHFH
FFFH
HFFG
or in the rendered window that is shown in the figure below
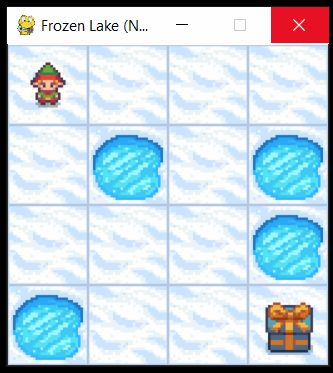
In our previous post which can be found here, we introduced the Frozen Lake problem and the corresponding environment. This environment is illustrated in the figure below.
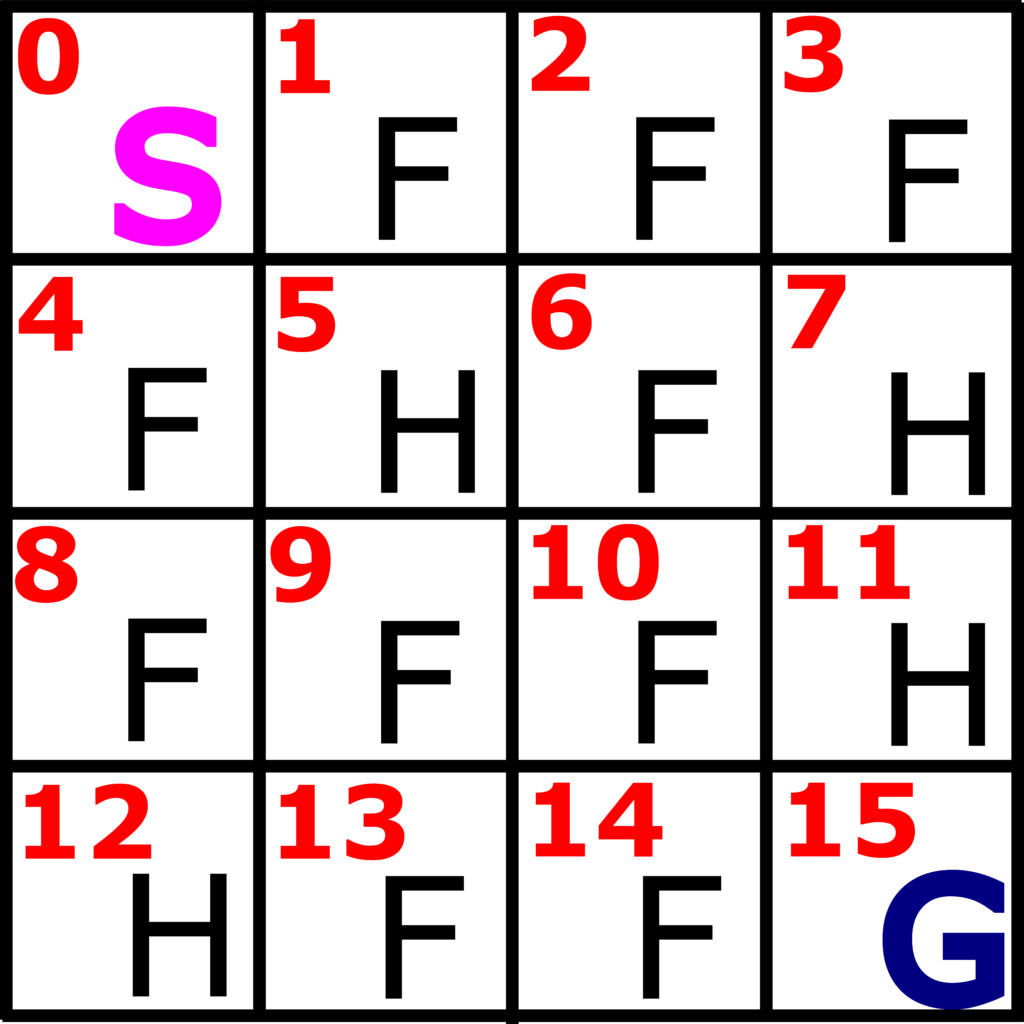
We have 16 states, denoted by 0,1,2,…,15. Every state corresponds to a certain field that can be a frozen field (F), hole (H), start state (S), of the goal state (G). Our goal is to reach the goal state starting from the start state and by avoiding the hole state. More information about this problem can be found in our previous post.
Important information related to the observation and action spaces can be obtained as follows
# observation space - states
env.observation_space
# actions: left -0, down - 1, right - 2, up- 3
env.action_space
We can generate random actions, perform a random step, and render the environment by executing these code lines
#generate random action
randomAction= env.action_space.sample()
returnValue = env.step(randomAction)
# format of returnValue is (observation,reward, terminated, truncated, info)
# observation (object) - observed state
# reward (float) - reward that is the result of taking the action
# terminated (bool) - is it a terminal state
# truncated (bool) - it is not important in our case
# info (dictionary) - in our case transition probability
env.render()
The function “env.action_space.sample()” samples a random action from the action space  . On the other hand, the function “env.step(randomAction)” performs the generated step, and returns the value. The returned value has the following form
. On the other hand, the function “env.step(randomAction)” performs the generated step, and returns the value. The returned value has the following form
(observation,reward, terminated, truncated, info)
In our case, we obtained
(0, 0.0, False, False, {‘prob’: 0.3333333333333333})
This implies that the final state is 0, reward is 0, “False” means that the final state is not a terminal state (we did not arrive at the hole or the goal state), another Boolean return value “False” is not important for this discussion, and {‘prob’: 0.3333333333333333} is the transition probability from our initial state 0 to state 0.
Deterministic actions can be performed by directly specifying the action
# perform deterministic step 0,1,2,3
returnValue = env.step(1)
We can return the environment to its original state by calling the rest function
# reset the environment
env.reset()
By executing this code on your computer, you might notice that when applying the action 1, that is the action “DOWN”, you will not always transition to the state below the current state. This is because the actual response of the environment is dictated by the transition probabilities. The transition probabilities can be accessed by typing env.P[state][action]. env.P is actually a dictionary containing all the transition probabilities. The following code lines illustrate transition probabilities:
#transition probabilities
#p(s'|s,a) probability of going to state s'
# starting from the state s and by applying the action a
# env.P[state][action]
env.P[0][1] #state 0, action 1
# output is a list having the following entries
# (transition probability, next state, reward, Is terminal state?)
The output of
env.P[0][1] #state 0, action 1
s
[(0.3333333333333333, 0, 0.0, False),
(0.3333333333333333, 4, 0.0, False),
(0.3333333333333333, 1, 0.0, False)]
This output should be interpreted as follows
(transition probability, next state, reward, Is terminal state?)
That is
- Transition probability from state 0 and under action 1 (DOWN) to state 0 is 1/3, obtained reward is 0, and the state 0 (final state) is not a terminal state.
- Transition probability from state 0 and under action 1 (DOWN) to state 4 is 1/3, obtained reward is 0, and the state 4 (final state) is not a terminal state.
- Transition probability from state 0 and under action 1 (DOWN) to state 1 is 1/3, obtained reward is 0, and the state 1 (final state) is not a terminal state.
Let us now see the transition probability env.P[6][1]
env.P[6][1]
The result is
[(0.3333333333333333, 5, 0.0, True),
(0.3333333333333333, 10, 0.0, False),
(0.3333333333333333, 7, 0.0, True)]
That is
- Transition probability from state 6 and under action 1 (DOWN) to state 5 is 1/3, the obtained reward is 0, and the state 5 (final state) is a terminal state.
- Transition probability from state 6 and under action 1 (DOWN) to state 10 is 1/3, obtained reward is 0, and the state 10 (final state) is not a terminal state.
- Transition probability from state 6 and under action 1 (DOWN) to state 7 is 1/3, obtained reward is 0, and the state 7 (final state) is a terminal state.
The following code lines explain how to simulate random episodes in OpenAI Gym. Random episodes are important for simulating reinforcement learning algorithms.
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 9 21:29:24 2022
@author: ahaber
"""
import gym
import time
env=gym.make("FrozenLake-v1",render_mode='human')
env.reset()
env.render()
print('Initial state of the system')
numberOfIterations=30
for i in range(numberOfIterations):
randomAction= env.action_space.sample()
returnValue=env.step(randomAction)
env.render()
print('Iteration: {} and action {}'.format(i+1,randomAction))
time.sleep(2)
if returnValue[2]:
break
env.close()
After importing the Gym environment and creating the Frozen Lake environment, we reset and render the environment. Then, we specify the number of simulation iterations (numberOfIterations=30). In every iteration of the for loop, we draw a random action and apply the random action to the environment. Then, if the returnValue[2]==”True”, we break the loop since in this case, we reach the terminal state and the simulation is completed. The terminal state can either be the hole state, in which case we lose, or the final state in which case we win.