 by
by
In our previous post, which can be found here, we explained how to derive the Kalman filter equations from scratch by using the recursive least squares method. In this post, we explain how to implement the Kalman filter in Python. For implementing the Kalman filter we will use an objected-oriented approach with the goal of creating a reusable and easy-to-understand code. The Python codes accompanying this tutorial are given here. The YouTube video accompanying this post is given below.
Summary of the Kalman Filter Equations
The Kalman filter equations that are derived in our previous tutorial, have the following form:
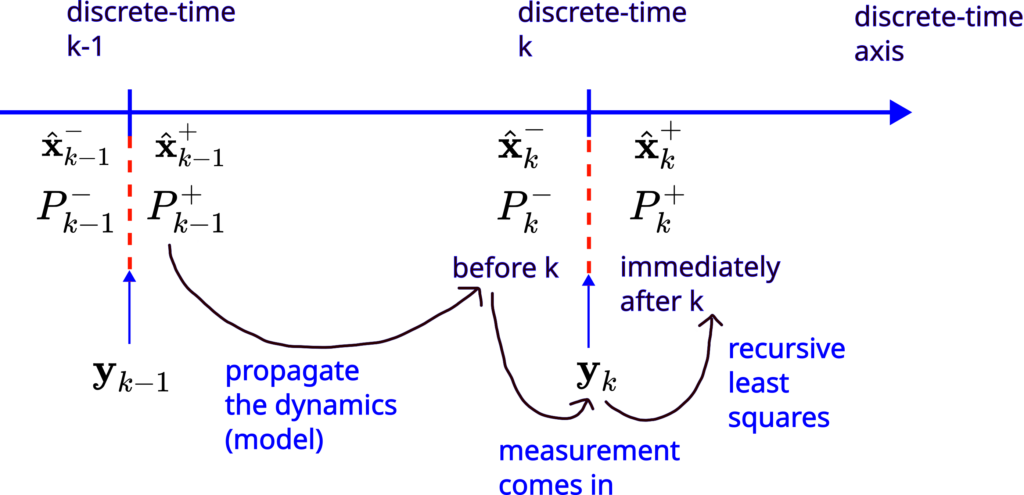
Step 1: Propagate the a posteriori estimate  and the covariance matrix of the estimation error
and the covariance matrix of the estimation error  , through the system dynamics to obtain the a priori state estimate and the covariance matrix of the estimation error for the step
, through the system dynamics to obtain the a priori state estimate and the covariance matrix of the estimation error for the step  :
:
(1) 
Step 2: Obtain the measurement  . Use this measurement, and the a priori estimate
. Use this measurement, and the a priori estimate  and the covariance matrix of the estimation error
and the covariance matrix of the estimation error  to compute the a posteriori state estimate and the covariance matrix of the estimation error
to compute the a posteriori state estimate and the covariance matrix of the estimation error
(2) 
In these equations, is the a priori state estimate,  is the a posterior state estimate, is the discrete-time instant,
is the a posterior state estimate, is the discrete-time instant,  and
and  are the system matrices,
are the system matrices,  is the process noise covariance matrix,
is the process noise covariance matrix,  is the measurement noise covariance matrix,
is the measurement noise covariance matrix,  is an identity matrix,
is an identity matrix,  is the a posteriori covariance matrix of the estimation error, and is the a priori covariance matrix of the estimation error.
is the a posteriori covariance matrix of the estimation error, and is the a priori covariance matrix of the estimation error.
These steps are graphically illustrated in Fig. 1 below.
Test Example
Here, we present a test example that will be used to check the implementation accuracy and performance. We consider a Newtonian particle moving with a constant acceleration  :
:
(3) 
where is the constant acceleration, and  is a position of the particle,
is a position of the particle,  is time, and
is time, and  is the second derivative of the position
is the second derivative of the position  . Physically, this system can be seen as a vehicle moving in a straight line with constant acceleration. By integrating the equation (3) twice, we obtain the position :
. Physically, this system can be seen as a vehicle moving in a straight line with constant acceleration. By integrating the equation (3) twice, we obtain the position :
(4) 
where  is an initial position and
is an initial position and  is an initial velocity,
is an initial velocity,
We assume that the acceleration is not known, as well as the initial position and initial velocity. We assume that only the position is measured. However, the position observations are corrupted by the measurement noise.
Our goal is to estimate the position  , velocity
, velocity  , and acceleration from the noisy observations of the position .
, and acceleration from the noisy observations of the position .
Our first goal is to write a state-space model corresponding to the system (3). We introduce the state-space variables
(5) 
(6) 
From (15), we have
(7) 
where  is the continuous state-space matrix. The next step is to discretize the state-space model (15). It is very well-known fact in control theory, that for the time interval of length
is the continuous state-space matrix. The next step is to discretize the state-space model (15). It is very well-known fact in control theory, that for the time interval of length  , we have
, we have
(8) 
By defining  and
and  , from (8), we obtain
, from (8), we obtain
(9) 
where the matrix  is defined
is defined
(10) 
The number is the discretization period or the sampling period. We need to compute the matrix exponential. For that purpose, we can use the series expansion
(11) 
Let us compute (11). We have
(12) 
(13) 
The powers of larger than  in (11) are zero. Consequently, they do not need to be computed. Taking this fact into account, and by substituting (12) and (13) in (11), we obtain
in (11) are zero. Consequently, they do not need to be computed. Taking this fact into account, and by substituting (12) and (13) in (11), we obtain
(14) 
Under the assumption that only the position  can be measured, our state-space model takes the following form
can be measured, our state-space model takes the following form
(15) 
where
(16) 
is the measurement matrix  and
and  is the scalar measurement noise, with the covariance matrix (in our case, the covariance matrix is a scalar variable)
is the scalar measurement noise, with the covariance matrix (in our case, the covariance matrix is a scalar variable)
(17) 
Here we assume that the process noise is zero. Consequently, the process noise covariance matrix  is a zero matrix.
is a zero matrix.
Object-oriented Python Implementation of the Kalman Filter
The Python codes accompanying this tutorial are given here. In the sequel, we explain these code files. We define a class called KalmanFilter. This class initializes and stores the important matrices and variables. Also, this class contains two methods (functions) that are implementing the step 1 and step 2 of the Kalman filter. The class implementation is given below.
class KalmanFilter(object):
# x0 - initial guess of the state vector
# P0 - initial guess of the covariance matrix of the state estimation error
# A,B,C - system matrices describing the system model
# Q - covariance matrix of the process noise
# R - covariance matrix of the measurement noise
def __init__(self,x0,P0,A,B,C,Q,R):
# initialize vectors and matrices
self.x0=x0
self.P0=P0
self.A=A
self.B=B
self.C=C
self.Q=Q
self.R=R
# this variable is used to track the current time step k of the estimator
# after every measurement arrives, this variables is incremented for +1
self.currentTimeStep=0
# this list is used to store the a posteriori estimates xk^{+} starting from the initial estimate
# note: list starts from x0^{+}=x0 - where x0 is an initial guess of the estimate
self.estimates_aposteriori=[]
self.estimates_aposteriori.append(x0)
# this list is used to store the a apriori estimates xk^{-} starting from x1^{-}
# note: x0^{-} does not exist, that is, the list starts from x1^{-}
self.estimates_apriori=[]
# this list is used to store the a posteriori estimation error covariance matrices Pk^{+}
# note: list starts from P0^{+}=P0, where P0 is the initial guess of the covariance
self.estimationErrorCovarianceMatricesAposteriori=[]
self.estimationErrorCovarianceMatricesAposteriori.append(P0)
# this list is used to store the a priori estimation error covariance matrices Pk^{-}
# note: list starts from P1^{-}, that is, P0^{-} does not exist
self.estimationErrorCovarianceMatricesApriori=[]
# this list is used to store the gain matrices Kk
self.gainMatrices=[]
# this list is used to store prediction errors error_k=y_k-C*xk^{-}
self.errors=[]
# this function propagates x_{k-1}^{+} through the model to compute x_{k}^{-}
# this function also propagates P_{k-1}^{+} through the covariance model to compute P_{k}^{-}
# at the end this function increments the time index currentTimeStep for +1
def propagateDynamics(self,inputValue):
xk_minus=self.A*self.estimates_aposteriori[self.currentTimeStep]+self.B*inputValue
Pk_minus=self.A*self.estimationErrorCovarianceMatricesAposteriori[self.currentTimeStep]*(self.A.T)+self.Q
self.estimates_apriori.append(xk_minus)
self.estimationErrorCovarianceMatricesApriori.append(Pk_minus)
self.currentTimeStep=self.currentTimeStep+1
# this function should be called after propagateDynamics() because the time step should be increased and states and covariances should be propagated
def computeAposterioriEstimate(self,currentMeasurement):
import numpy as np
# gain matrix
Kk=self.estimationErrorCovarianceMatricesApriori[self.currentTimeStep-1]*(self.C.T)*np.linalg.inv(self.R+self.C*self.estimationErrorCovarianceMatricesApriori[self.currentTimeStep-1]*(self.C.T))
# prediction error
error_k=currentMeasurement-self.C*self.estimates_apriori[self.currentTimeStep-1]
# a posteriori estimate
xk_plus=self.estimates_apriori[self.currentTimeStep-1]+Kk*error_k
# a posteriori matrix update
IminusKkC=np.matrix(np.eye(self.x0.shape[0]))-Kk*self.C
Pk_plus=IminusKkC*self.estimationErrorCovarianceMatricesApriori[self.currentTimeStep-1]*(IminusKkC.T)+Kk*(self.R)*(Kk.T)
# update the lists that store the vectors and matrices
self.gainMatrices.append(Kk)
self.errors.append(error_k)
self.estimates_aposteriori.append(xk_plus)
self.estimationErrorCovarianceMatricesAposteriori.append(Pk_plus)
The initialization function initialized the initial guess of the posteriori estimate, initial guess of the a posteriori covariance matrix of the estimation error, system matrices, and covariance matrices of the measurement and process noise (code lines 12-18). Here, for simplicity, we assume that all the matrices are constant. The presented codes can easily be modified to take into account the time-varying system dynamics. The variable self.currentTimeStep defined on the code line 22 is used to store the current time step . Every time we call the function propagateDynamics(self,inputValue) on the code line 51, we increment the variable self.currentTimeStep for +1. The function propagateDynamics(self,inputValue) is used to implement the step 1 of the Kalman filter defined by the equation (1). The list self.estimates_aposteriori=[] initialized on the code line 26 is used to store the a posteriori estimate  . We add an initial guess of the estimate on the code line 27 to this list. On the other hand, the list
. We add an initial guess of the estimate on the code line 27 to this list. On the other hand, the list self.estimates_apriori=[] initialized on the code line 31 is used to store the a priori estimate  . The list self.estimationErrorCovarianceMatricesAposteriori=[] for storing the a posteriori covariance matrices is initialized on the code line 35. The initial guess of the covariance matrix is added to this list. On the other hand, the list
. The list self.estimationErrorCovarianceMatricesAposteriori=[] for storing the a posteriori covariance matrices is initialized on the code line 35. The initial guess of the covariance matrix is added to this list. On the other hand, the list self.estimationErrorCovarianceMatricesApriori=[] for storing the a priori covariance matrix is initialized on the code line 40. The code line 43 defines the list self.gainMatrices=[] for storing the Kalman gain matrices  . Finally, on the code line 46, we initialize the list
. Finally, on the code line 46, we initialize the list self.errors=[] storing the a priori prediction errors  that are used to compute (2).
that are used to compute (2).
The function propagateDynami(csself,inputValue) on the code line is used to implement the first step of the Kalman filter
(18) 
This function takes as an input the control input  , and computes the a priori estimate and the a priori covariance matrix. On the other hand, the function
, and computes the a priori estimate and the a priori covariance matrix. On the other hand, the function computeAposterioriEstimate(self,currentMeasurement) on the code line 62 is used to implement the second step of the Kalman filter
(19) 
This function takes an input , and it computes the Kalman filter gain and a posteriori estimation as well as the a posteriori covariance matrix.
Next, we explain how to use this class. We use the previously explained example to test the Kalman filter class. First, we import the necessary libraries and define the discretization step as well as the initial position, initial velocity, and acceleration for simulating the Newtonian particle (4). We also select the measurement noise standard deviation and number of simulation time steps.
import numpy as np
import matplotlib.pyplot as plt
from KalmanFilter import KalmanFilter
# discretization step
h=0.1
# initial values for the simulation
initialPosition=10
initialVelocity=-5
# acceleration
acceleration=0.5
# measurement noise standard deviation
noiseStd=1;
# number of discretization time steps
numberTimeSteps=100
Then, we define the system matrices, covariance matrices, and initial guesses
# define the system matrices - Newtonian system
# system matrices and covariances
A=np.matrix([[1,h,0.5*(h**2)],[0, 1, h],[0,0,1]])
B=np.matrix([[0],[0],[0]])
C=np.matrix([[1,0,0]])
R=1*np.matrix([[1]])
Q=np.matrix(np.zeros((3,3)))
#guess of the initial estimate
x0=np.matrix([[0],[0],[0]])
# initial covariance matrix
P0=1*np.matrix(np.eye(3))
Then, we simulate the model (??) to obtain the data for testing the Kalman filter
# time vector for simulation
timeVector=np.linspace(0,(numberTimeSteps-1)*h,numberTimeSteps)
# vector used to store the simulated position
position=np.zeros(np.size(timeVector))
velocity=np.zeros(np.size(timeVector))
# simulate the system behavior
for i in np.arange(np.size(timeVector)):
position[i]=initialPosition+initialVelocity*timeVector[i]+(acceleration*timeVector[i]**2)/2
velocity[i]=initialVelocity+acceleration*timeVector[i]
# add the measurement noise
positionNoisy=position+noiseStd*np.random.randn(np.size(timeVector))
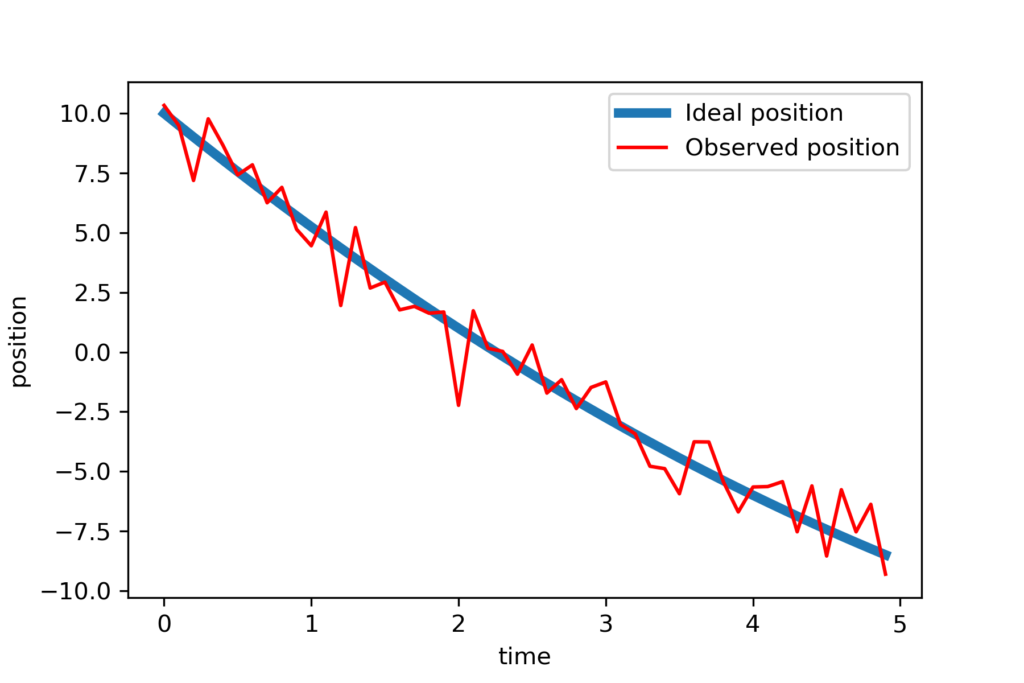
The vector positionNoisy is our noise corrupted position and the entries of this vector are . We plot the noise-free and noisy position:
# verify the position vector by plotting the results
plotStep=numberTimeSteps//2
plt.plot(timeVector[0:plotStep],position[0:plotStep],linewidth=4, label='Ideal position')
plt.plot(timeVector[0:plotStep],positionNoisy[0:plotStep],'r', label='Observed position')
plt.xlabel('time')
plt.ylabel('position')
plt.legend()
plt.savefig('data.png',dpi=300)
plt.show()
The results are shown in the figure below.
Next, we create a KalmanFilter object and simulate the Kalman filter equations:
#create a Kalman filter object
KalmanFilterObject=KalmanFilter(x0,P0,A,B,C,Q,R)
inputValue=np.matrix([[0]])
# simulate online prediction
for j in np.arange(np.size(timeVector)):
KalmanFilterObject.propagateDynamics(inputValue)
KalmanFilterObject.computeAposterioriEstimate(positionNoisy[j])
KalmanFilterObject.estimates_aposteriori
The for loop iterates over the time vector. The call of the function KalmanFilterObject.propagateDynamics(inputValue) computes the step (18). On the other hand, the call of the function KalmanFilterObject.computeAposterioriEstimate(positionNoisy[j]) computes the step (19). We can obtain the computed estimates by executing this code line: KalmanFilterObject.estimates_aposteriori.
Finally, we can visualize the estimates by executing these code lines:
# extract the state estimates in order to plot the results
estimate1=[]
estimate2=[]
estimate3=[]
for j in np.arange(np.size(timeVector)):
estimate1.append(KalmanFilterObject.estimates_aposteriori[j][0,0])
estimate2.append(KalmanFilterObject.estimates_aposteriori[j][1,0])
estimate3.append(KalmanFilterObject.estimates_aposteriori[j][2,0])
# create vectors corresponding to the true values in order to plot the results
estimate1true=position
estimate2true=velocity
estimate3true=acceleration*np.ones(np.size(timeVector))
# plot the results
steps=np.arange(np.size(timeVector))
fig, ax = plt.subplots(3,1,figsize=(10,15))
ax[0].plot(steps,estimate1true,color='red',linestyle='-',linewidth=6,label='True value of position')
ax[0].plot(steps,estimate1,color='blue',linestyle='-',linewidth=3,label='Estimate of position')
ax[0].set_xlabel("Discrete-time steps k",fontsize=14)
ax[0].set_ylabel("Position",fontsize=14)
ax[0].tick_params(axis='both',labelsize=12)
#ax[0].set_yscale('log')
#ax[0].set_ylim(98,102)
ax[0].grid()
ax[0].legend(fontsize=14)
ax[1].plot(steps,estimate2true,color='red',linestyle='-',linewidth=6,label='True value of velocity')
ax[1].plot(steps,estimate2,color='blue',linestyle='-',linewidth=3,label='Estimate of velocity')
ax[1].set_xlabel("Discrete-time steps k",fontsize=14)
ax[1].set_ylabel("Velocity",fontsize=14)
ax[1].tick_params(axis='both',labelsize=12)
#ax[0].set_yscale('log')
#ax[1].set_ylim(0,2)
ax[1].grid()
ax[1].legend(fontsize=14)
ax[2].plot(steps,estimate3true,color='red',linestyle='-',linewidth=6,label='True value of acceleration')
ax[2].plot(steps,estimate3,color='blue',linestyle='-',linewidth=3,label='Estimate of acceleration')
ax[2].set_xlabel("Discrete-time steps k",fontsize=14)
ax[2].set_ylabel("Acceleration",fontsize=14)
ax[2].tick_params(axis='both',labelsize=12)
#ax[0].set_yscale('log')
#ax[1].set_ylim(0,2)
ax[2].grid()
ax[2].legend(fontsize=14)
fig.savefig('plots.png',dpi=600)
As the result, we obtain the following graph
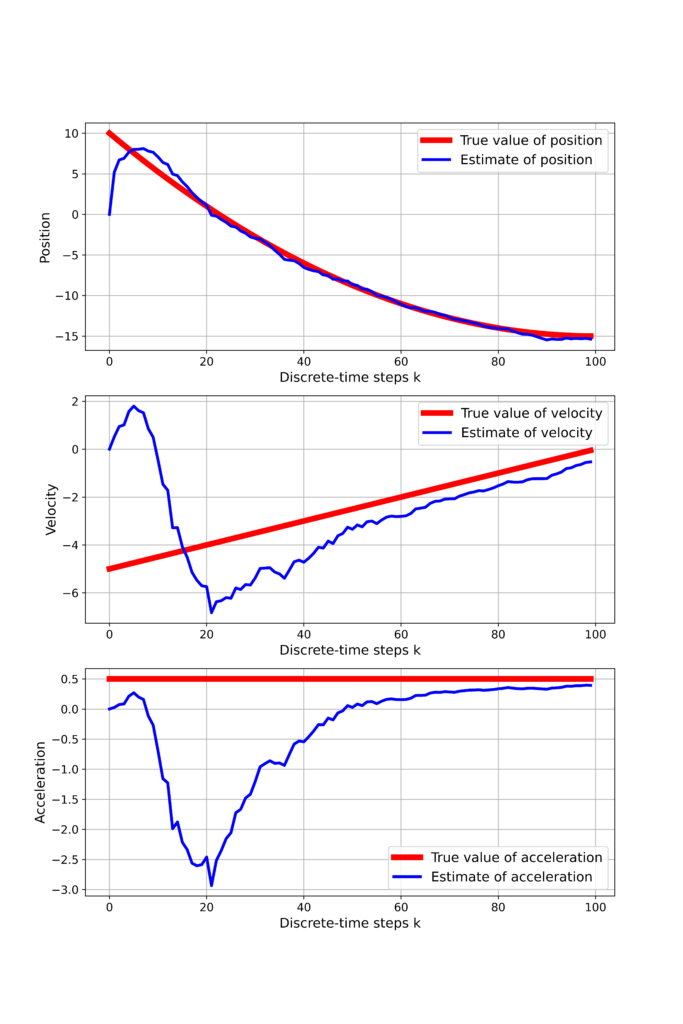
From Figure 3 we can observe that all 3 states eventually converge to the true values.