 by
by
In this tutorial series, we explain how to formulate and numerically solve different versions of the nonlinear Model Predictive Control (MPC) problem. We implement the solution in MATLAB. The focus of this series is mainly on the practical implementation without going too deep into the theoretical aspects of nonlinear MPC. You are currently reading Tutorial 1. In this tutorial, we explain how to formulate an open-loop nonlinear MPC problem and how to approximate its solution in MATLAB. The YouTube video accompanying this webpage is given below.
Before reading this tutorial and watching the video, we suggest that you go over our previous tutorial on the linear MPC implementation given here. The developed MATLAB code can be found over here (fee needs to be paid). The YouTube tutorial explaining the implementation is given below.
How to Cite this Document and Tutorial:
To cite this document and tutorial:
“Practical Introduction to Nonlinear Model Predictive Control with MATLAB Implementation”. Technical Report, Number 1, Aleksandar Haber, (2024), Publisher: www.aleksandarhaber.com, Link: https://aleksandarhaber.com/nonlinear-model-predictive-control-mpc-tutorial-1-open-loop-formulation-and-solution-in-matlab/.
When citing the report, include the link to this webpage!
Continuous-time Formulation of the Open-Loop Nonlinear Model Predictive Control Problem
Here, for presentation clarity and completeness, we first briefly formulate a continuous-time open-loop MPC problem. We focus on the open-loop control problem. The open-loop means that we predict and compute the complete future control input sequence at the initial time step, without shifting the time step and without observing the state at the shifted time step. That is, we assume that once it is computed at the initial time step, the complete future control sequence is applied at the subsequent time steps. This strategy can easily be modified to develop a closed-loop MPC algorithm (see our previous tutorial given here).
Here it should be kept in mind that the continuous-time formulation is rarely used in practice. The issue is that this problem is infinite-dimensional, and usually, it cannot be solved directly. Instead, this problem is usually discretized, and additional assumptions are introduced before it can be solved. This will be explained in the next section.
We consider a nonlinear dynamical system in the general form (we will introduce examples later on):
(1) 
where
 is the n-dimensional state vector.
is the n-dimensional state vector.  is the m-dimensional control input vector.
is the m-dimensional control input vector.  is a nonlinear state function that maps states and inputs into the n-dimensional derivative vector of states.
is a nonlinear state function that maps states and inputs into the n-dimensional derivative vector of states.
The goal of the MPC algorithm is to track a reference (desired) state trajectory. This trajectory should be designed by the user. In typical position control of mechanical systems, this trajectory consists of the user-defined position and velocity profiles. Let the desired reference trajectory be denoted by  .
.
Before we formulate the nonlinear MPC problem, we need to introduce the concept of the continuous-time prediction and control horizon denoted by  . The continuous-time prediction and control horizon denotes the time duration of the time horizon over which we predict the state trajectory as well as formulate and solve the control problem. The prediction and computation are performed at the initial time step (time step 0) of the prediction and control horizon, and the computed control sequence is applied to the actual system during the control horizon.
. The continuous-time prediction and control horizon denotes the time duration of the time horizon over which we predict the state trajectory as well as formulate and solve the control problem. The prediction and computation are performed at the initial time step (time step 0) of the prediction and control horizon, and the computed control sequence is applied to the actual system during the control horizon.
We assume that the complete state vector at the beginning of the prediction and control horizon is given or directly measured. In the MPC problem formulation given below, we assume that the start time instant of the prediction and control horizon is  . Consequently, we assume that
. Consequently, we assume that  is given. The MPC problem is illustrated in Fig. 1 below.
is given. The MPC problem is illustrated in Fig. 1 below.
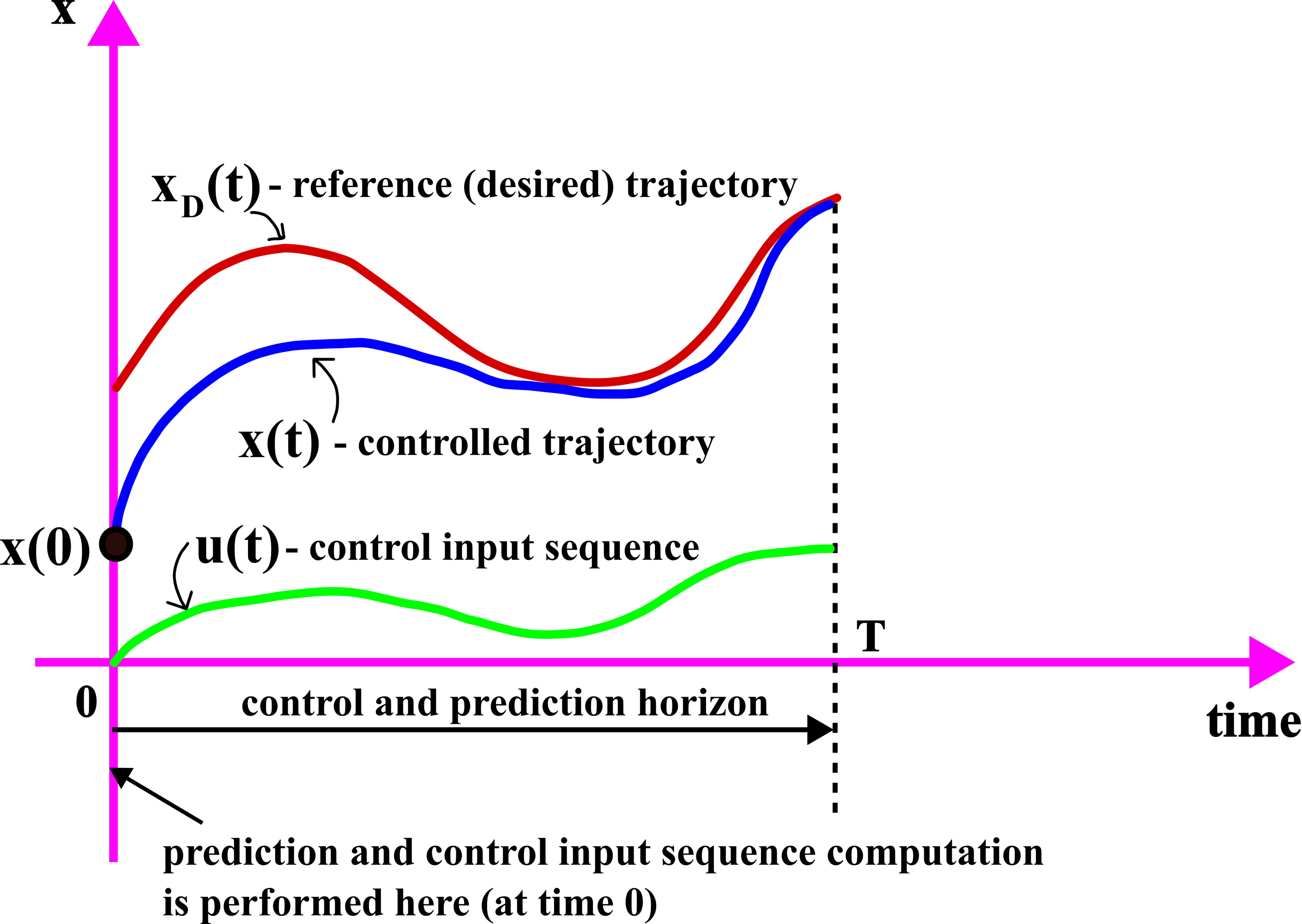
The nonlinear MPC problem for tracking a reference trajectory  can be defined as follows.
can be defined as follows.
(2) 
In (2),
 is the weighting matrix penalizing the state. We can use this matrix to tune the MPC control algorithm.
is the weighting matrix penalizing the state. We can use this matrix to tune the MPC control algorithm.  and
and  are the constant and known vectors defining the control input bounds. They encode the physical limitations of the actuators.
are the constant and known vectors defining the control input bounds. They encode the physical limitations of the actuators.
Note that the cost function in (2) is an integral over time of the weighted control error (the term  is the control error). Also, in this tutorial, for simplicity and brevity, we have only penalize the control inputs and not state trajectories. State constraints can also easily be incorporated into the optimization problem. This will be explained in our future tutorials.
is the control error). Also, in this tutorial, for simplicity and brevity, we have only penalize the control inputs and not state trajectories. State constraints can also easily be incorporated into the optimization problem. This will be explained in our future tutorials.
If we would be able to somehow solve the optimization problem (2), then the solution would be a continuous-time control input function
(3) 
However, in the most general case, it is practically impossible to compute an analytical form of the control input function given by (3). One of the main difficulties is that the optimization (2) is infinite-dimensional.
The way to solve this problem is to approximate the problem by a finite-dimensional problem. This is explained in the next section.
Discrete-time and Discretized Formulation of the Open-Loop Nonlinear Model Predictive Control Problem
The first step is to introduce a finite-dimensional control input sequence. We assume that instead of searching for a continuous time control input sequence (3), we search for a discrete-time and finite control input sequence
(4) 
where
(5) 
and where  is a discretization constant, and
is a discretization constant, and  is a discrete-time instant. Here, the last time instant
is a discrete-time instant. Here, the last time instant  corresponds to the control horizon . That is,
corresponds to the control horizon . That is,  . In this way, we split the prediction and control time horizon
. In this way, we split the prediction and control time horizon ![[0,T]](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-4abaefab36f5ff9954ce7e19702699d5_l3.png "Rendered by QuickLaTeX.com") into the
into the  equidistant time instants:
equidistant time instants:
(6) 
The positive integer number is called the discrete-time prediction and control horizon.
Next, we assume that the control inputs are constant between the discrete-time instants  and
and  . That is, we assume the following
. That is, we assume the following
(7) 
The control inputs are shown in the figure below.
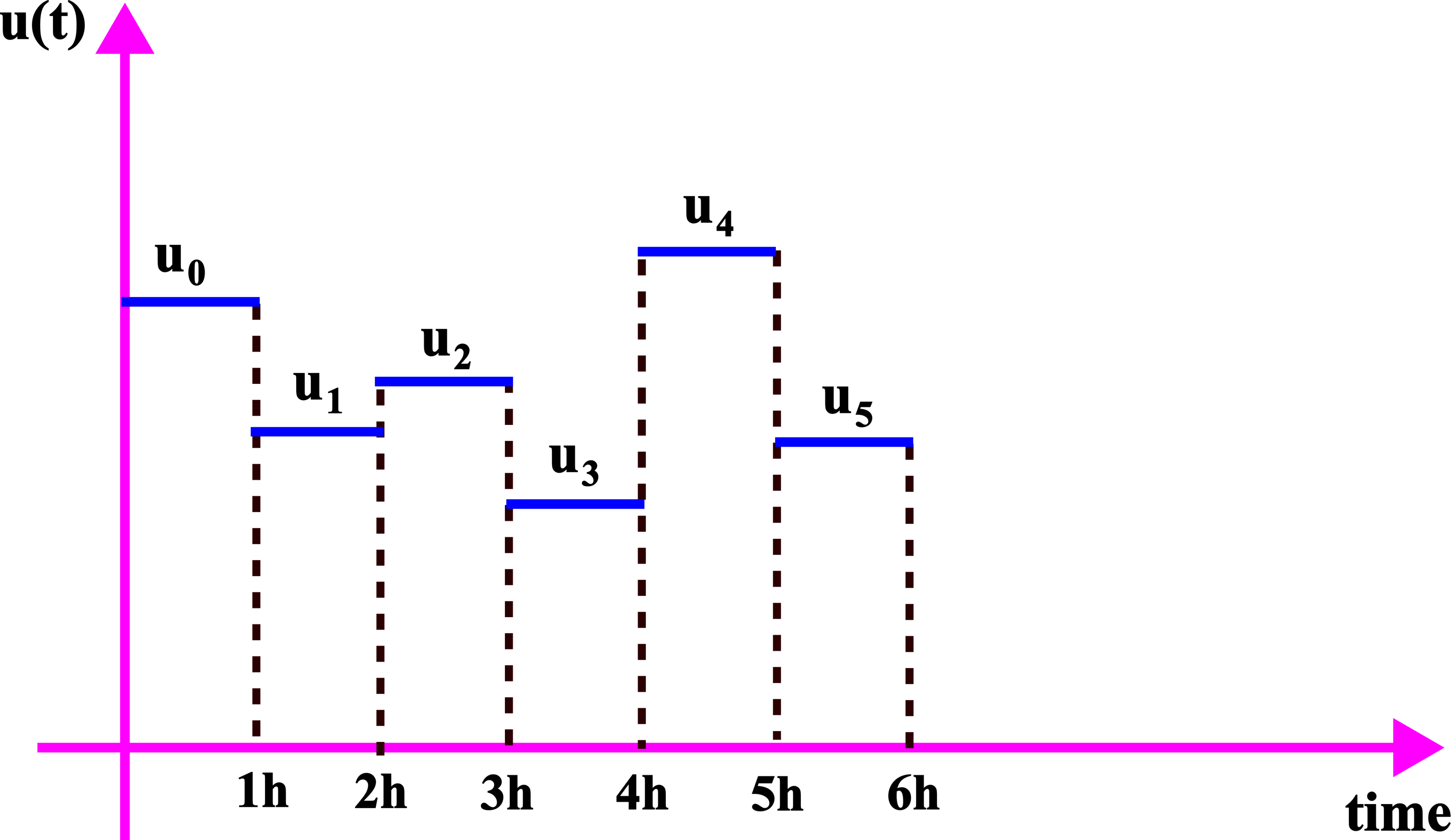
The next step is to discretize the continuous dynamics (1). Here, we can use explicit or implicit discretization schemes or even the discretization scheme used by MATLAB’s ode45() solver (we actually use the ode45 solver in our MATLAB simulations). For the presentation clarity, we will formally use the discretized dynamics obtained by using an explicit time-forward discretization. By discretizing (1) and under the assumption of the constant input between the time samples, we obtain the discrete-time state equation representing the discretized dynamics:
(8) 
where  is the discretized state-space dynamics, and
is the discretized state-space dynamics, and  is the discretized state vector at the time instant
is the discretized state vector at the time instant  . That is,
. That is,  .
.
Note that the equation (8) is written only for presentation clarity and in order to illustrate the main ideas. In the MATLAB implementation, we will not use this equation, instead, we will use the ode45 solver to obtain a discrete-time state sequence .
Next, we discretize the cost function (2). By approximating the integral by a sum, we obtain the following cost function
(9) 
In (9):
 is the discretized reference (desired) trajectory at the time instant
is the discretized reference (desired) trajectory at the time instant  . That is,
. That is,  .
.  is the weight function at the time instant . That is,
is the weight function at the time instant . That is,  .
.
Finally, we obtain the discrete-time formulation of the nonlinear model predictive control (MPC) problem
(10) 
Let us group all the optimization variables in a single vector
(11) 
When implementing the solution of the optimization problem (10), it is important to keep in mind the following
- Any optimization solver for the above problem iteratively computes the optimization variable
 , starting from some guess of . When is fixed, and due to the fact that the initial condition
, starting from some guess of . When is fixed, and due to the fact that the initial condition  is known, we can simulate the discretized dynamics (8) to obtain the state sequence
is known, we can simulate the discretized dynamics (8) to obtain the state sequence  . That is, in every iteration of the optimization solver, the discrete states in the cost function can be substituted by their numerical values. Since the reference trajectory is known, in every iteration of the optimization solver, we can evaluate the cost function. This is enough for implementing the solution of the optimization problem in MATLAB. We can use an interior point method to solve the problem.
. That is, in every iteration of the optimization solver, the discrete states in the cost function can be substituted by their numerical values. Since the reference trajectory is known, in every iteration of the optimization solver, we can evaluate the cost function. This is enough for implementing the solution of the optimization problem in MATLAB. We can use an interior point method to solve the problem. - We do not need to know the gradients of the cost function in order to implement the solution in MATLAB. This is explained in the video. However, by computing the gradient, we can significantly speed up the computations. This will be explored in our future tutorials.
Examples
We will test the MPC algorithm by using two examples. The first example is a linear mass-spring-damper system in the state-space form
(12) 
where  ,
,  , and
, and  are the model constants.
are the model constants.
The second example is a nonlinear system represented by the following state-space model
(13) 
Control Results – First Example
The first example is defined by the following parameters:  ,
,  , and
, and  .
.
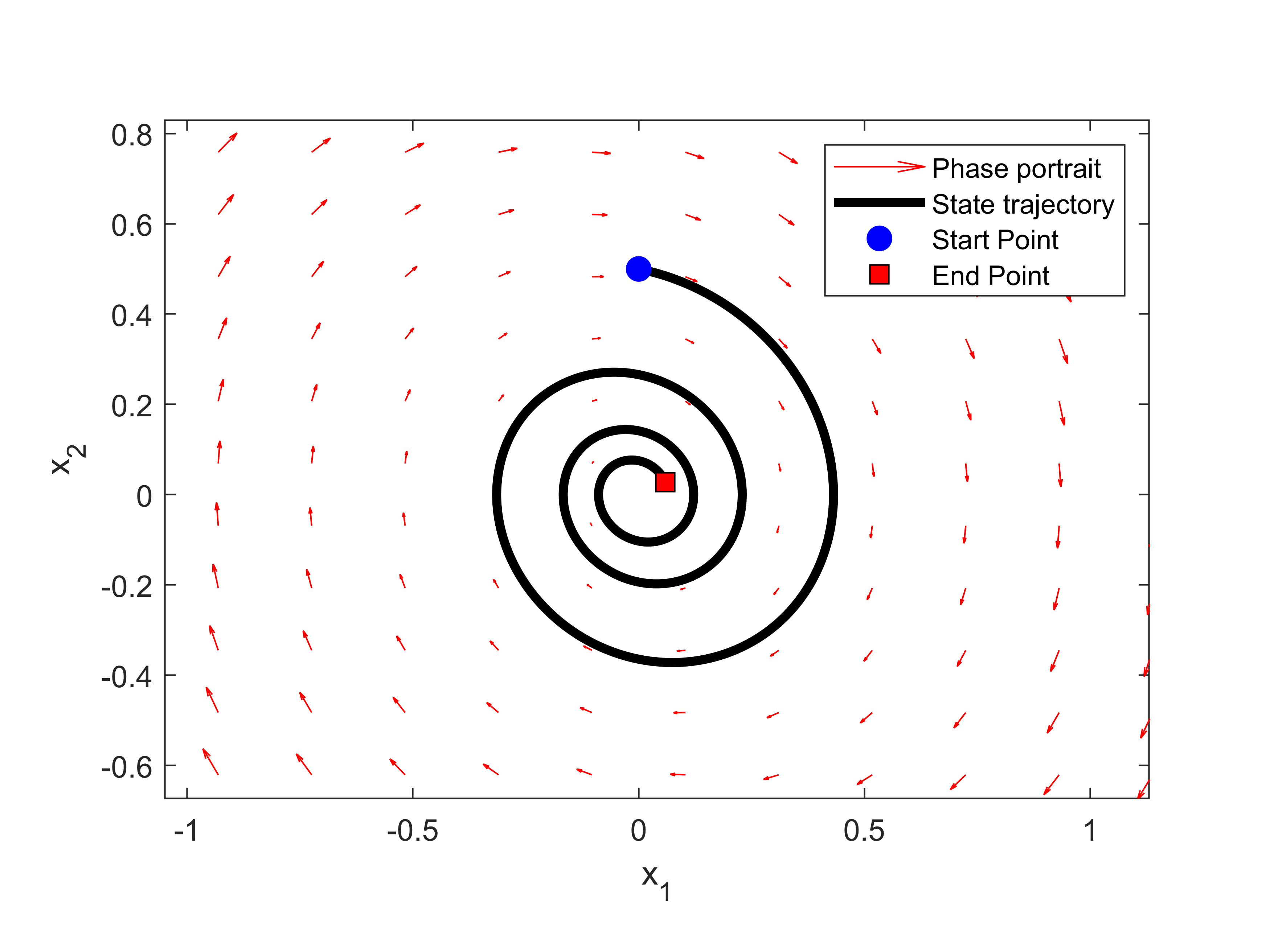
The figure below shows a simulated phase portrait and a single trajectory.
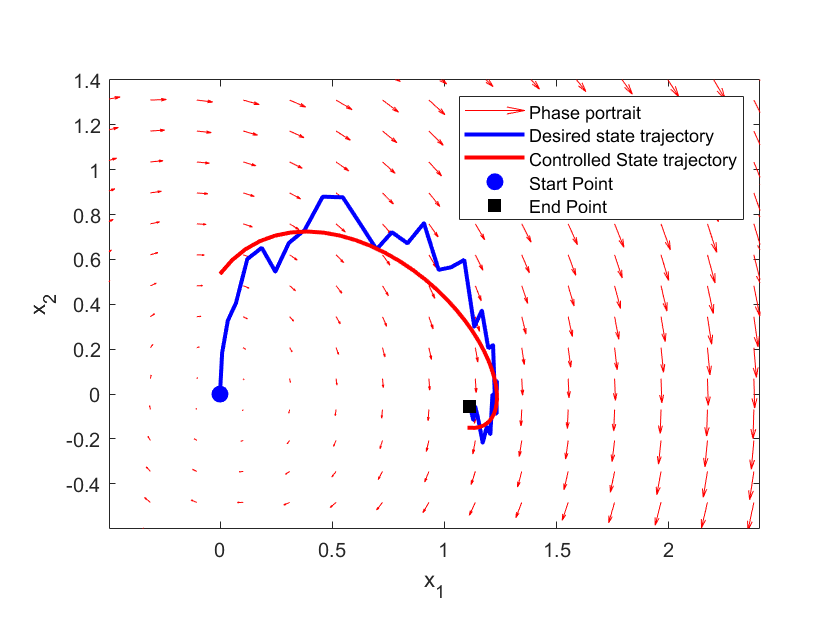
The figure below shows the desired and controlled state-space trajectory. The controlled trajectory is controlled by using the solution of the MPC problem.
The time representation of the desired value of  and the controlled value of is shown below.
and the controlled value of is shown below.
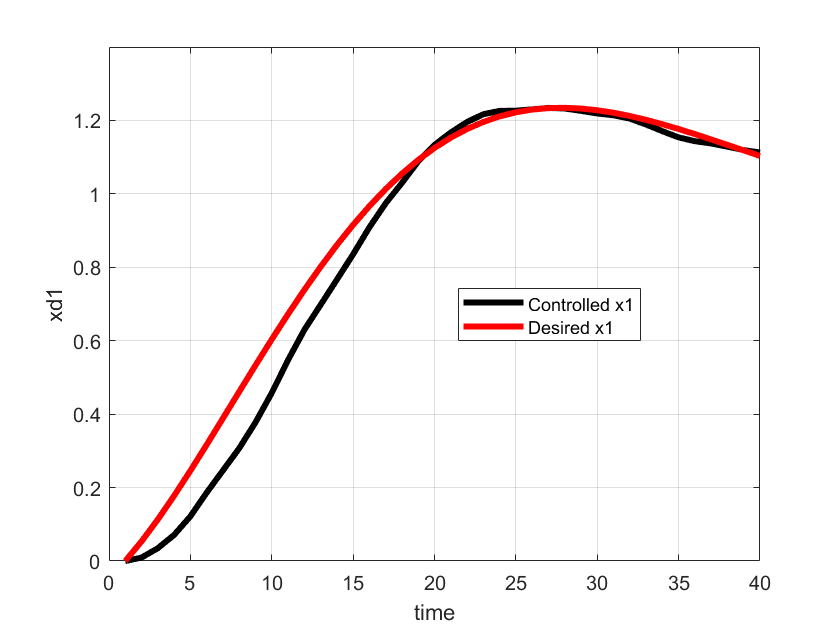 .
.Control Results – Second Example
The second example is defined by the following parameters:  ,
,  ,
,  ,
,  , and
, and  .
.
The phase portrait is given below and a single trajectory is given in the figure below.
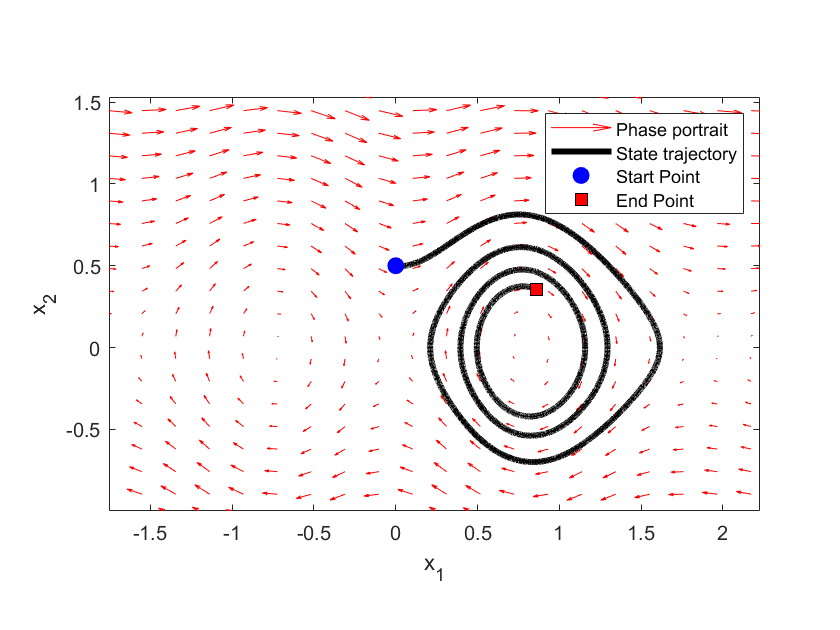
The figure below shows the desired and controlled state-space trajectory. The controlled trajectory is controlled by using the solution of the MPC problem.
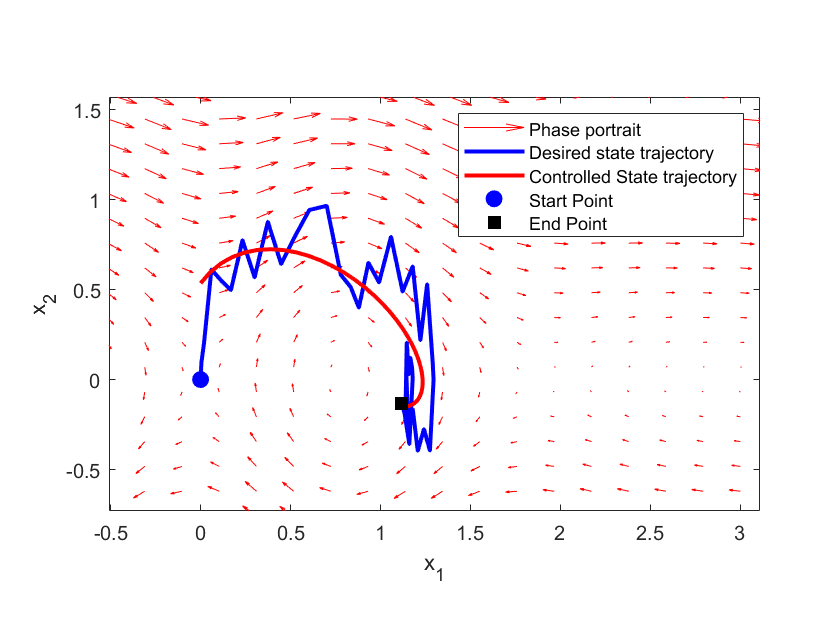
The time representation of the desired value of and the controlled value of is shown below.
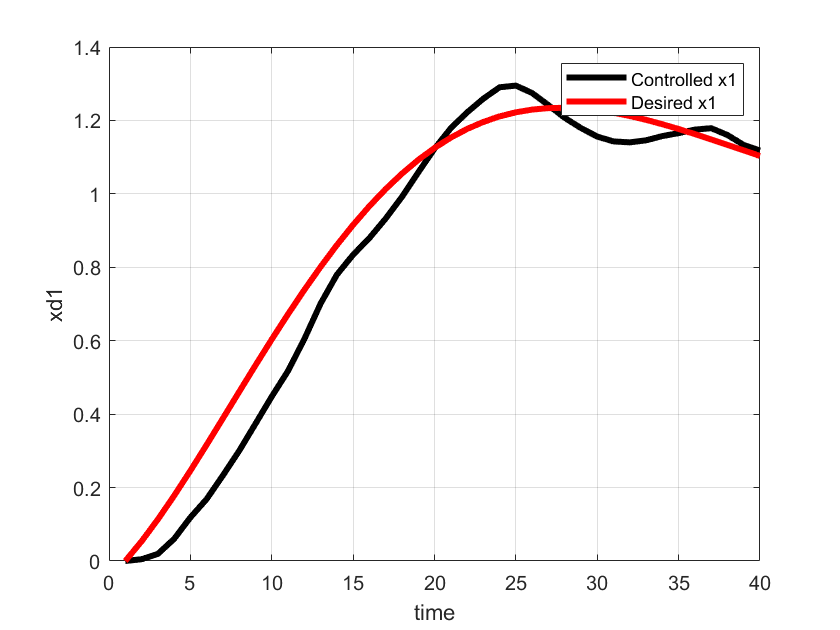 .
.