 by
by In this machine learning and large language model tutorial, we explain how to compile and build llama.cpp program with GPU support from source on Windows. For readers of this tutorial who are not familiar with llama.cpp, llama.cpp is a program for running large language models (LLMs) locally. You can run the model with a single command line. Once we explain how to build llama.cpp, we explain how to run Microsoft’s Phi-4 LLM. The YouTube tutorial is given below.
The main reason for building llama.cpp from scratch comes from the fact that our experience shows that the binary version of llama.cpp that can be found online does not fully exploit the GPU resources. To make sure that that llama.cpp fully exploits the GPU card, we need to build llama.cpp from scratch by using the CUDA and C++ compilers.
Prerequisites
- You need to install Microsoft Visual Studio C++ and Microsoft Visual Studio C++ compilers. This is necessary for building the llama.cpp from source. To install Microsoft Visual Studio C++, go to this website and download and install Microsoft Visual Studio C++ Community edition.
- You need to install the CUDA Toolkit in order to be able to compile lamma.cpp with CUDA support. To download and install the CUDA Toolkit, go to this website and download and later on install the file.
- You need to install Git such that you can download the source files. To install and download Git, and download and install the Git installation file.
Install and Build Lllama.cpp
Next, open Microsoft Visual Studio Developer Command Prompt, and first verify that CUDA compilers are installed and they are in the path
To verify that the CUDA compilers are installed, type
nvcc --version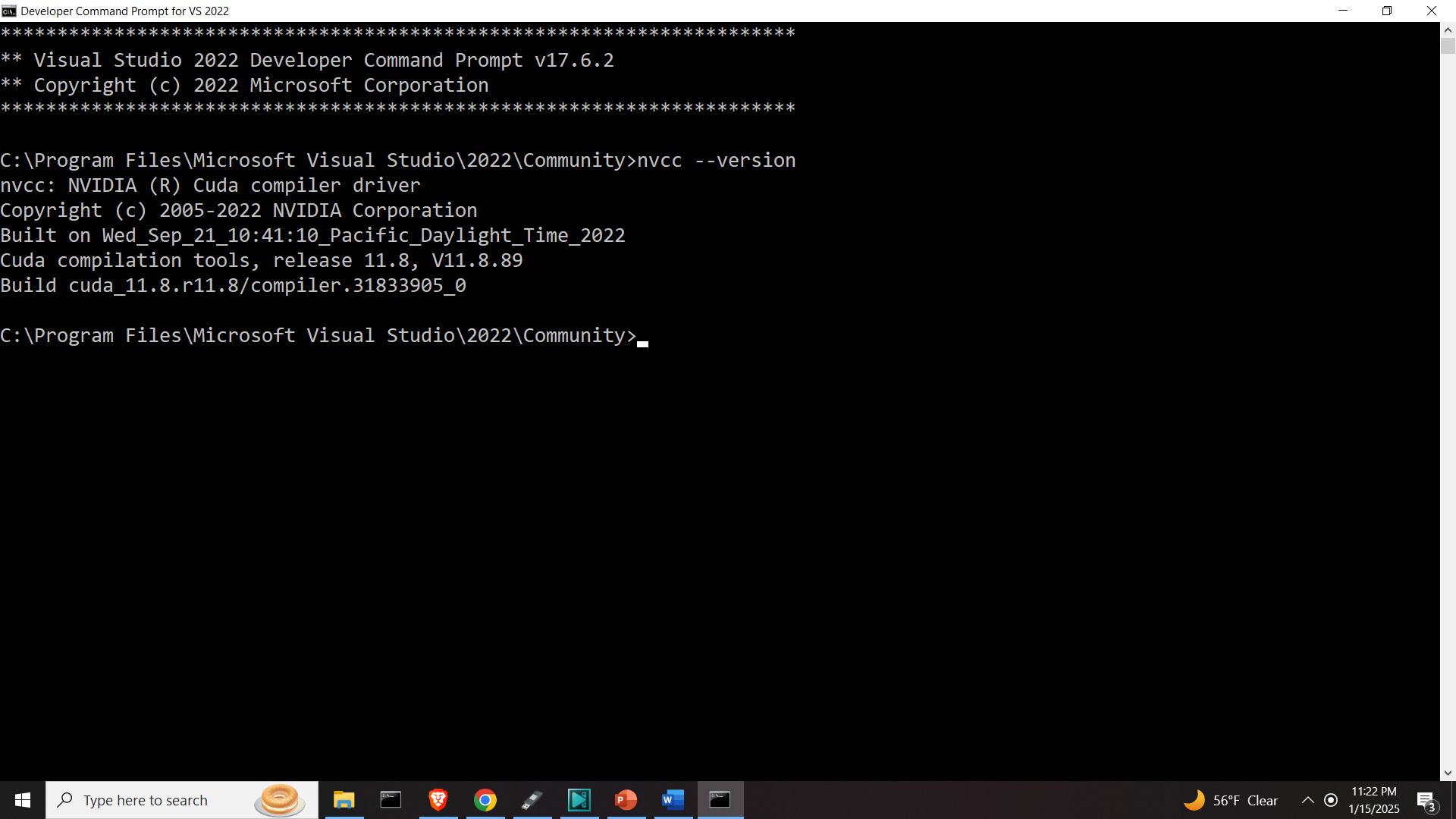
The output should be similar to
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Wed_Oct_30_01:18:48_Pacific_Daylight_Time_2024
Cuda compilation tools, release 12.6, V12.6.85
Build cuda_12.6.r12.6/compiler.35059454_0
Then verify that Git is installed, by simply typing
gitand you should get the generic response on how to use Git. Then create a workspace folder, and clone the remote llama.cpp repository
cd\
mkdir testLlama
git clone https://github.com/ggerganov/llama.cpp
Then, navigate the llama.cpp and build the project
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
cmake --build build --config ReleaseIt will take around 20-30 minutes to build everything. Once llama.cpp is compiled, then go to the Huggingface website and download the Phi-4 LLM file called phi-4-gguf.
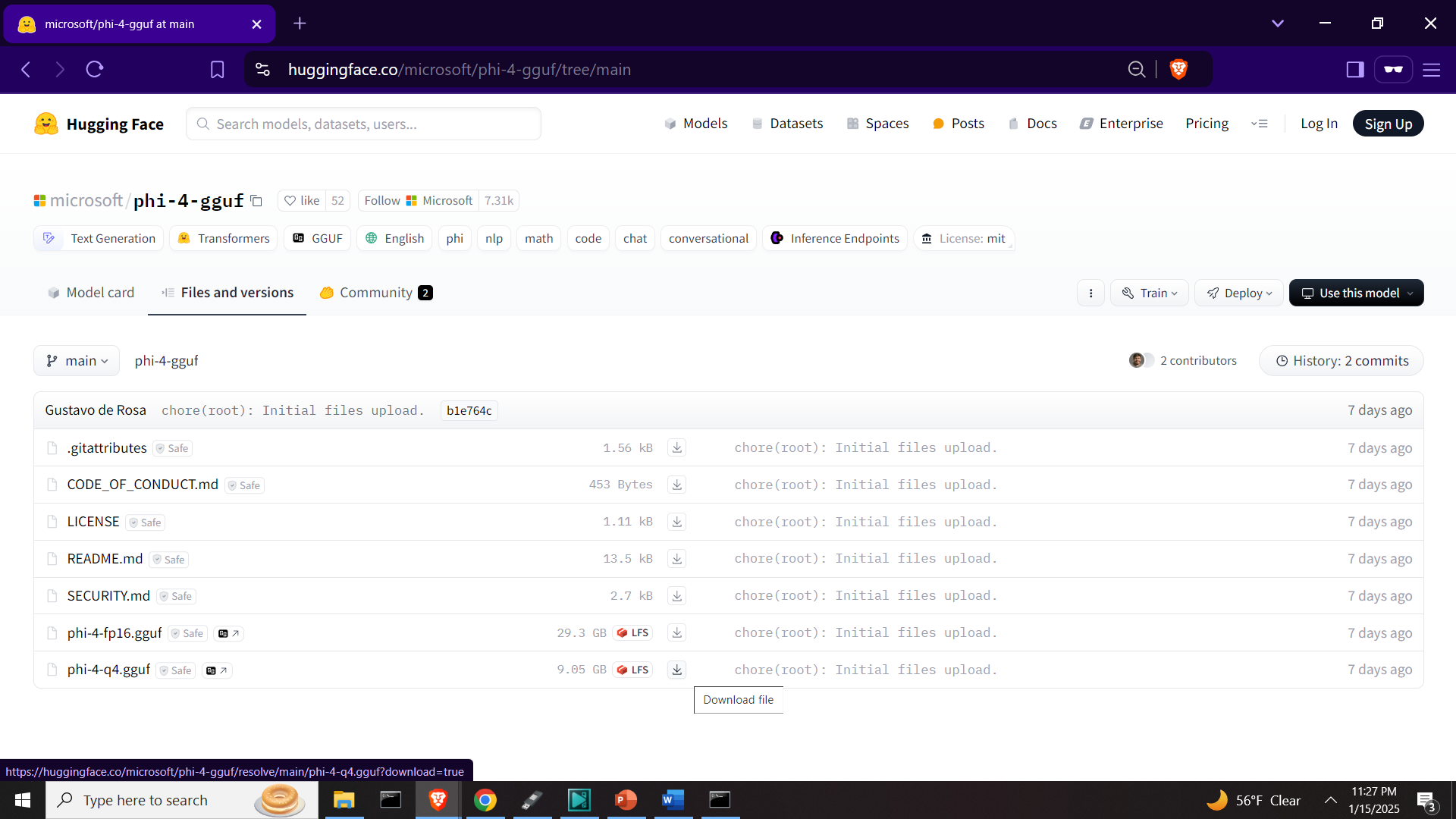
Then, copy this model file to
C:\testLlama\llama.cpp\build\bin\Release>where the executable files of llama.cpp are located. To run the model, navigate to this folder
cd C:\testLlama\llama.cpp\build\bin\Releaseand run the model by typing
llama-cli --model phi-4-q4.gguf -cnv -c 16384This will start the model Phi-4 in the interactive mode and ask the question to the model.