 by
by What is covered in this tutorial: In this particular tutorial, we explain how to use Ollama and Llama 3.1 through LangChain, and we will provide an introduction to chaining and prompt templates in LangChain. In particular, we explain how to install Ollama, Llama 3.1, and LangChain in Python and Windows. We will write two test codes explaining how to use Ollama in LangChain. Everything will be done through Python virtual environments. The YouTube tutorial is given below.
Motivation and big picture: Our goal is to create a series of tutorials on how to develop Retrieval Augmented Generation (RAG) applications from scratch by using open-source Large Language Models (LLMs). RAG applications combine (augment) LLMs with additional knowledge databases (documents, reports, tables, etc.) to improve the outputs of LLMs or to obtain intelligent conclusions from the provided knowledge database. This means that we are giving an LLM an additional library that should be used to provide answers to our questions and queries.
The ultimate goal is to develop a personal AI-based assistant that can analyze our documents, tables, images, etc.
In these tutorials, we will use Ollama and LangChain to run and test different LLMs. We selected Ollama since it enables us to easily run a number of powerful LLMs locally. In particular, we will extensively use and test Llama 3.1 LLM. On the other hand, we will use LangChain (as well as some other libraries) to develop the RAG application that is based on Ollama.
Installation Procedure of Ollama and Llama
Let us install Ollama and Llama. You can skip this step if you already have them on your system. To download and install Ollama, go to this webpage, and download the Windows installer of Ollama. Then install Ollama. After the installation, Ollama will be running in the background. Then open a Command Prompt and type:
ollama The output should look like this
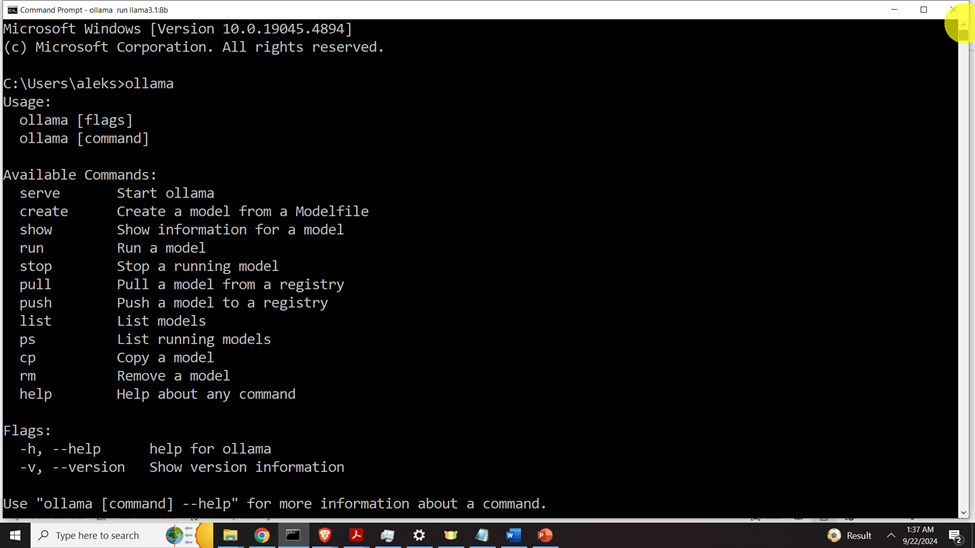
if you see such an output, this means that Ollama is properly installed on your system. The next step is to install the model. To install the model, go to the Llama 3.1 page inside of Ollama (follow this link)
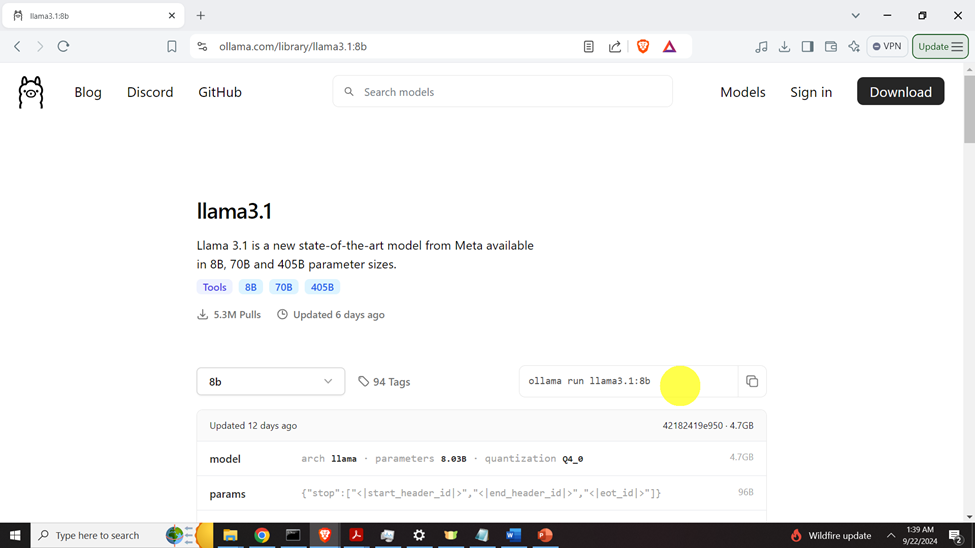
Then, copy and paste the generated command (see the yellow circle in the above image)
ollama run llama3.1:8bThis should download and install the model, and after that the model will be automatically started. You can ask a question to the model, to make sure that it is working properly.
Code that Explains How to Use Ollama and Llama in LangChain
First, we need to create a Python virtual environment, and then we need to install the Python libraries. Open a Windows Command Prompt and type
cd\
mkdir codes
cd codes
mkdir langChainTest
cd langChainTest
Create a virtual environment:
python -m venv env1Activate virtual environment
env1\Scripts\activate.batInstall Ollama Python API
pip install ollamaInstall LangChain – Ollama integration library
pip install -qU langchain-ollamaThe first test code is given here
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, SystemMessage
# update the model here
model = ChatOllama(model="llama3.1:8b")
messages = [
SystemMessage(content="Please provide the answer to the following question:"),
HumanMessage(content="What are the top 3 largest cities in the world."),
]
# call our model
response=model.invoke(messages)
# print the reponse
print(response.content)
# let us save the response in the file
with open('output.txt','w',encoding="utf-8") as text_file:
text_file.write(response.content)
The second test code is given here
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
# update the model here
model = ChatOllama(model="llama3.1:8b")
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"List {number} synonyms of the word specified by human.",
),
("human", "{word}"),
]
)
chain = prompt | model
result= chain.invoke(
{
"number": "6",
"word": "smart",
}
)
print(result.content)