 by
by In this tutorial, we explain how to install and run a (quantized) version of DeepSeek-V3 on a local computer by using the llama.cpp program. DeepSeek-V3 is a powerful Mixture-of-Experts (MoE) language model that according to the developers of DeepSeek-V3 outperforms other LLMs, such as ChatGPT and Llama. The YouTube tutorial is given below.
– We will install and run a quantized version of DeepSeek-V3 on a local computer.
Prerequisites:
– 200 GB of disk space for the smallest model and more than 400 GB disk space for the larger models.
– Significant amount of RAM memory. In our case, we have 48 GB of RAM memory and the model inference is relatively slow. Probably the inference speed can be improved by adding more RAM memory.
– Decent GPU. We performed tests on NVIDIA 3090 GPU with 24 GB VRAM. Better GPU will definitely increase the inference speed. After some tests we realized that the GPU resources are not used fully. This can be improved by building the llama.cpp from the source. This will be explored in the future tutorials
How to Install and Run DeepSeek-V3 Locally
The first step is to install the C++ compiler. For that purpose go the the Microsoft Visual Studio C++ website, and download Microsoft Visual Studio C++ Community Edition:
https://visualstudio.microsoft.com/vs/features/cplusplus
The second step is to install the CUDA toolkit:
https://developer.nvidia.com/cuda-toolkit
The next step is download and install llama.cpp. To download llama.cpp, go to this website
https://github.com/ggerganov/llama.cpp/releases
and download the file
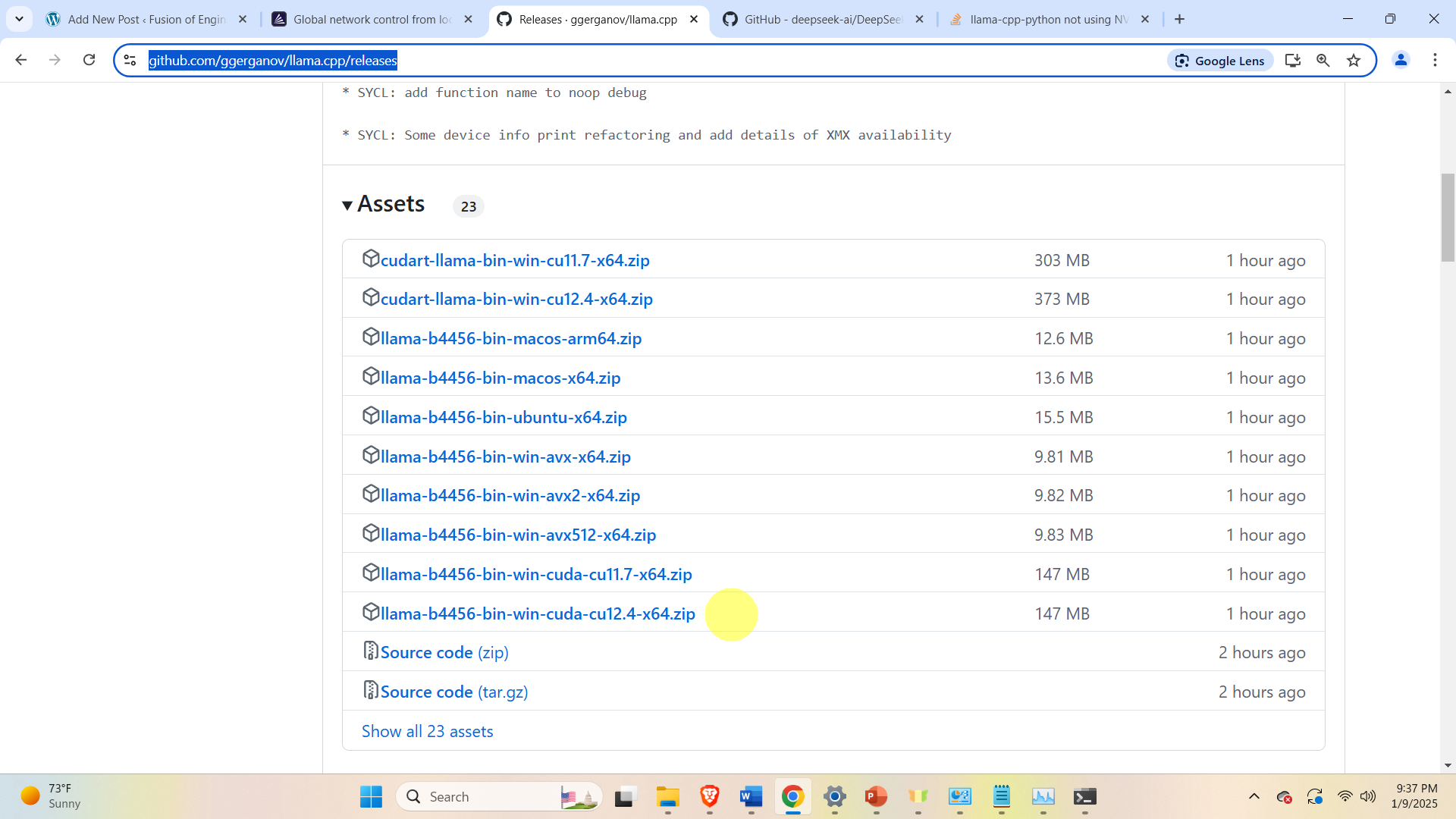
The file should be in the form llama-***-bin-win-cuda-cu***-x64.zip. Download this file, and unzip it. Then, copy all the downloaded files to a new folder. In our case, the name of the new folder is test12
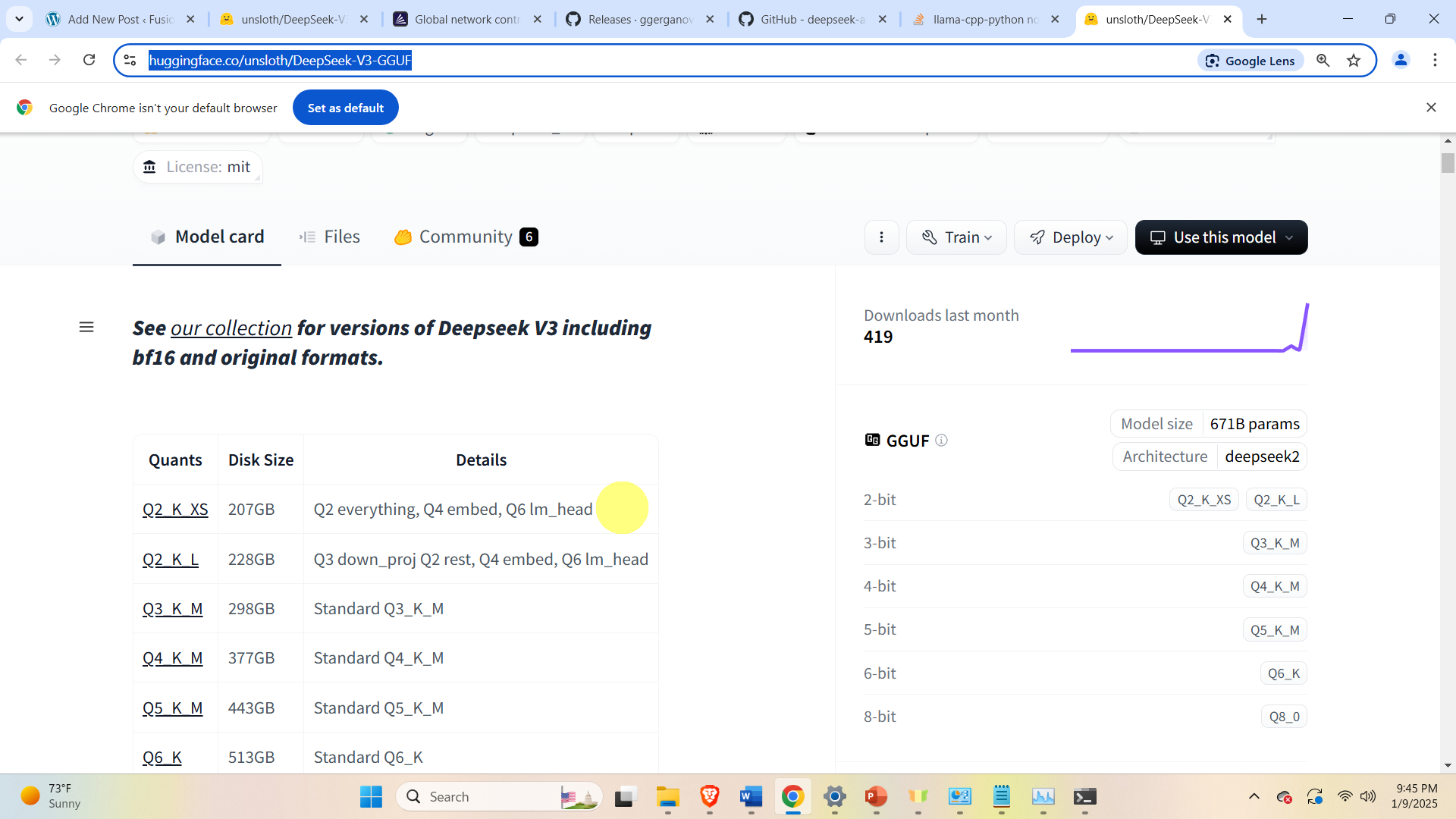
Then, download the DeepSeek model files. For that purpose go the Huggingface website
https://huggingface.co/unsloth/DeepSeek-V3-GGUF
and click on the desired model, and download all the 5 model files. We have selected the model. In our case, we select the model Q2_K_XS and download the files
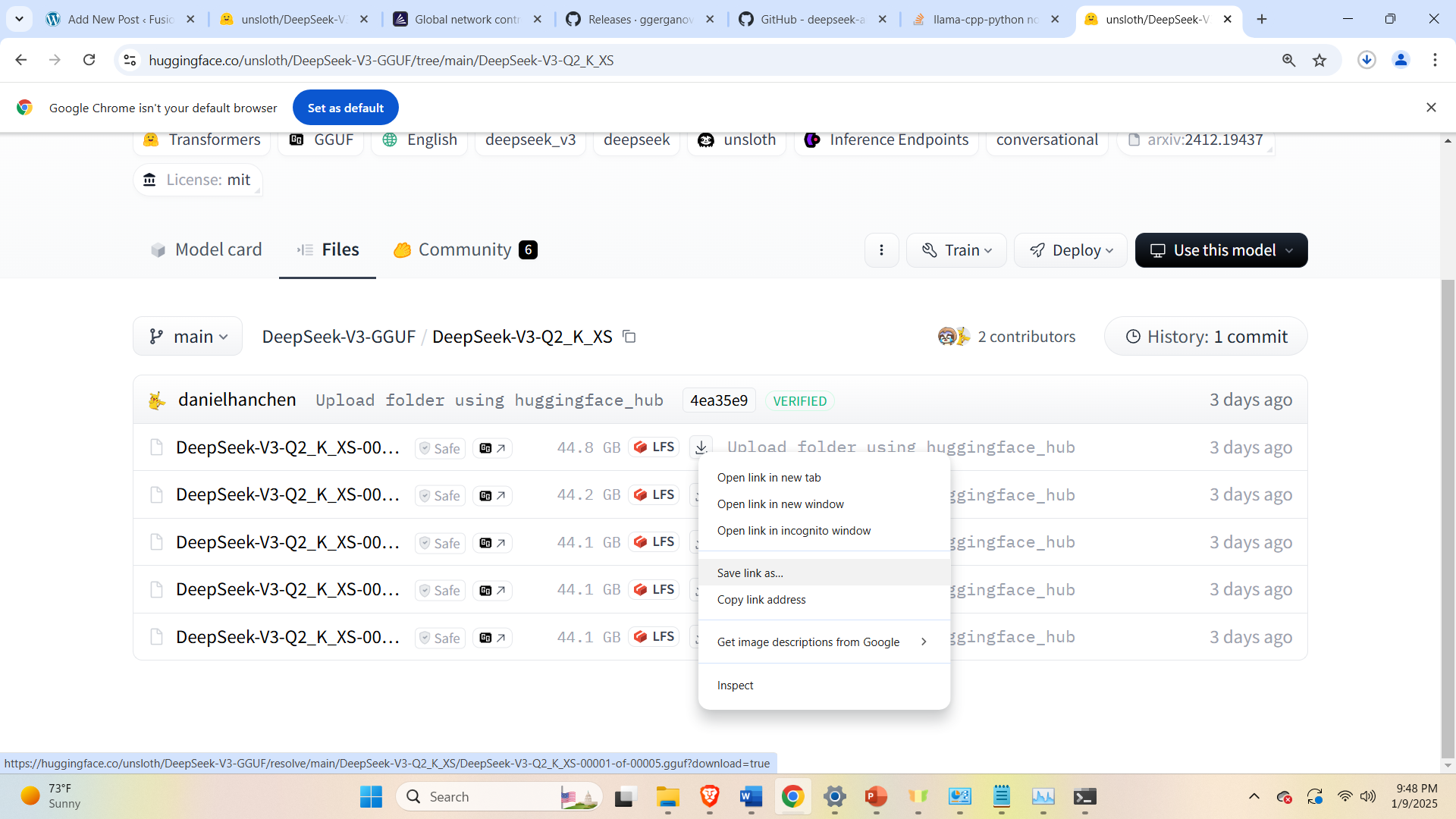
While downloading all 5 files, make sure to save them in the folder in which llama.cpp files are extracted. In our case, the name of the folder is test12
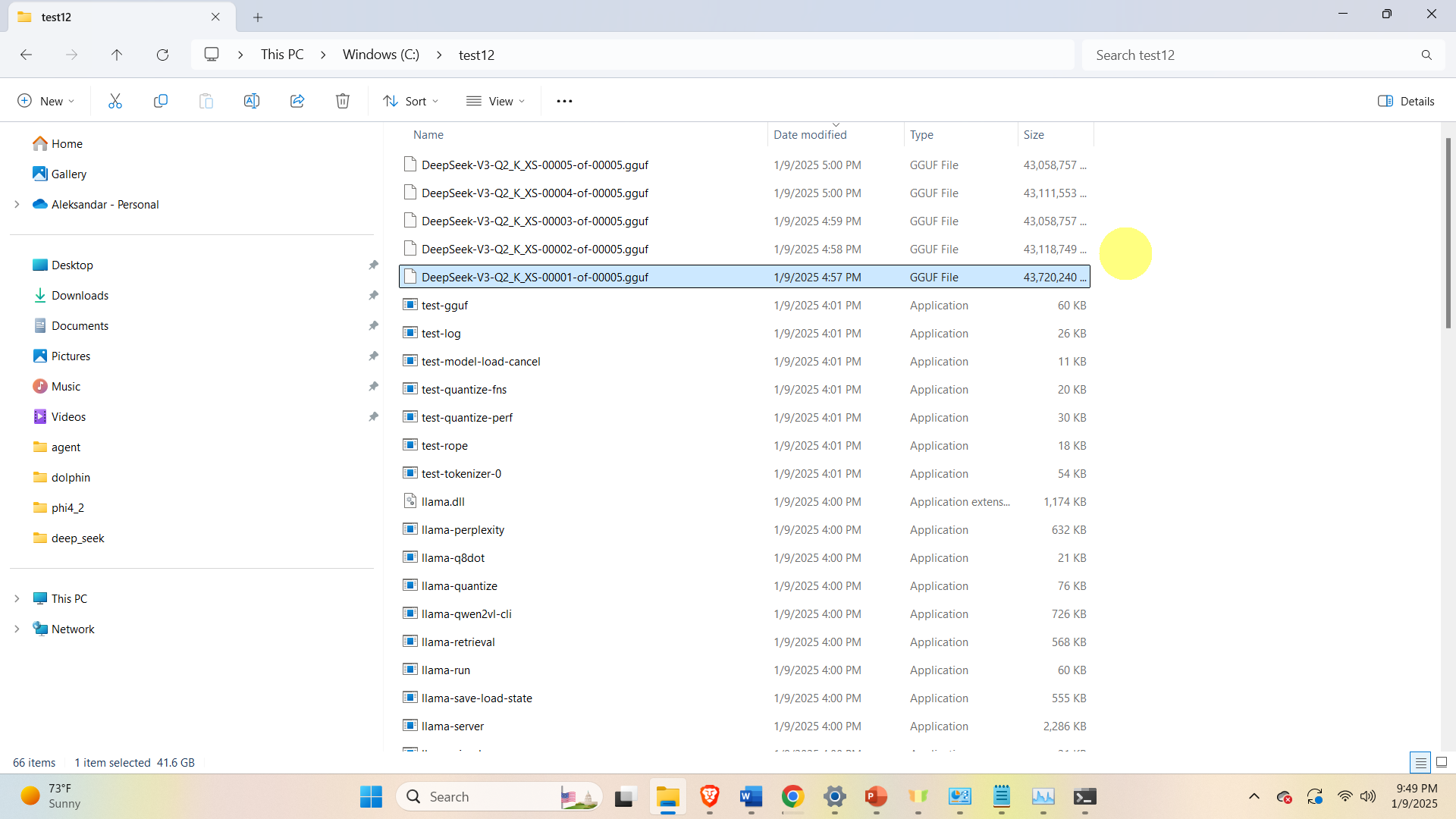
After the model is downloaded, we can run the model. Open a Command Prompt and navigate to the folder in which llama.cpp and model files are saved. In that folder type the following:
llama-cli --model DeepSeek-V3-Q2_K_XS-00001-of-00005.gguf --cache-type-k q5_0 --threads 16 --prompt "<|User|>How to solve a quadratic equation?<|Assistant|>"Here, the question with proper formatting is
"<|User|>How to solve a quadratic equation?<|Assistant|>"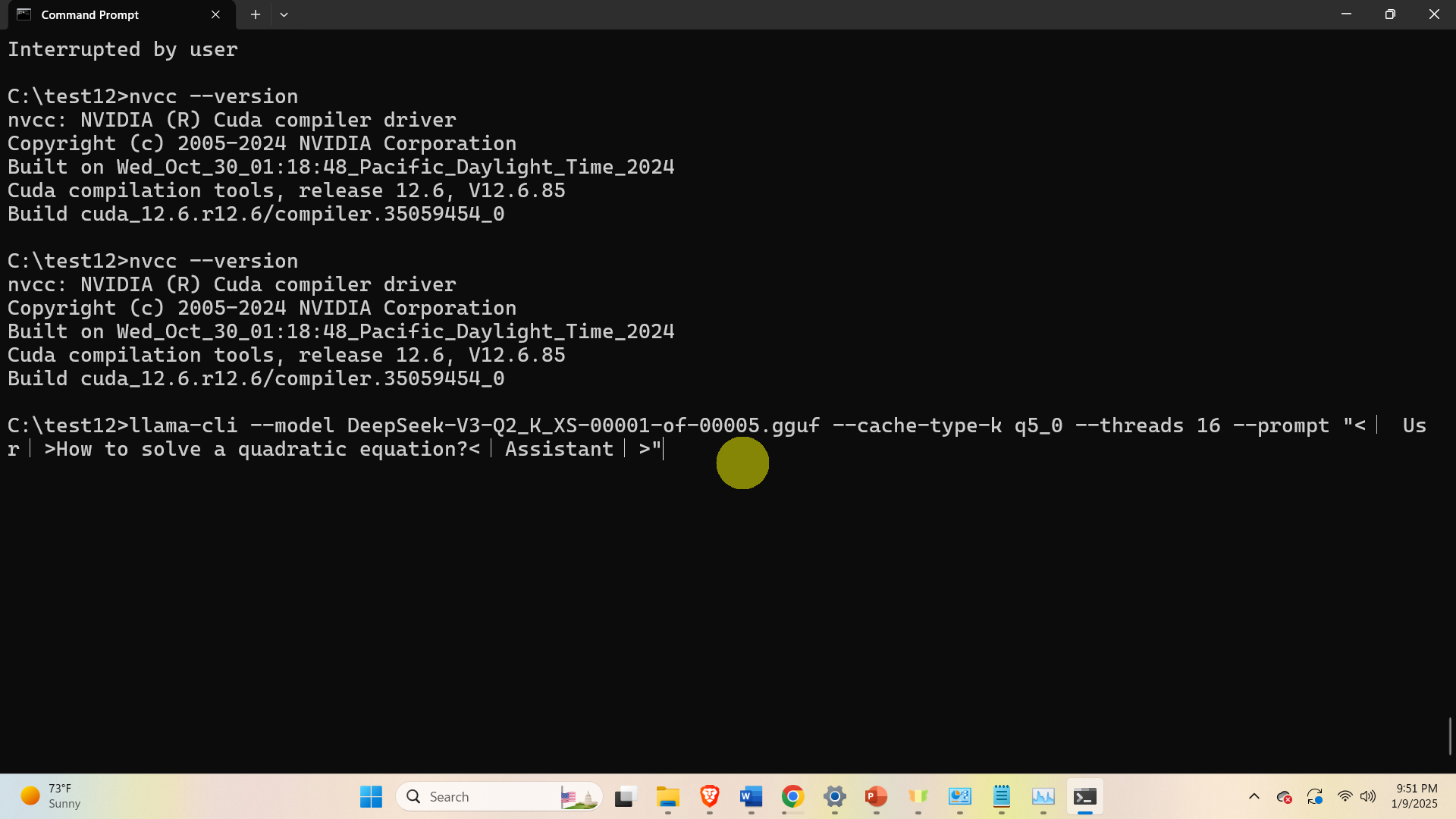
This should run the model.