 by
by In this tutorial, we provide an easy-to-understand explanation of the batch gradient descent method and we explain how to implement this method in Python. The YouTube page accompanying this tutorial is given below.
Batch Gradient Descent Method
In order to be able to understand this tutorial, we suggest to the interested reader to revise the concept of gradient, which is explained in our previous tutorial whose link is given here.
In this tutorial, we explain how the concept of gradient can be used to solve optimization problems in batch form. We present the batch gradient descent method. The name of this method is the batch gradient descent method which is also known as the steepest descent method and gradient descent method. The word “batch” refers to the data batch, that is, optimization problems in the batch form depend on a data batch:
(1) 
where
 are data points. These data points represent the data batch.
are data points. These data points represent the data batch.
Here, for presentation clarity, we assume that these data points are related through a linear model. However, everything explained in this tutorial can easily be generalized to nonlinear models. Let us assume that the data points are related through a linear model that we want to estimate
(2) 
where  and
and  are parameters of the linear model that we need to estimate. The previous equation is an ideal representation of a physical system or a process. For example, the model (2) can represent a calibration curve of our sensor. For example,
are parameters of the linear model that we need to estimate. The previous equation is an ideal representation of a physical system or a process. For example, the model (2) can represent a calibration curve of our sensor. For example,  might be a measured voltage,
might be a measured voltage,  can a physical variable that we are interested in observing, such as distance, pressure, or temperature. The parameters and are unknown parameters of the model that need to be estimated. In practice, the model (2) is always corrupted by measurement noise.
can a physical variable that we are interested in observing, such as distance, pressure, or temperature. The parameters and are unknown parameters of the model that need to be estimated. In practice, the model (2) is always corrupted by measurement noise.
The goal is to estimate the parameters and , from the set of batch data .
By using the data points and from (2), we have
(3) 
where  represent measurement noise for every data point
represent measurement noise for every data point  ,
,  .
.
To estimate the parameters, we form the batch cost function:
(4) 
and we form the batch optimization problem
(5) 
This optimization problem is a linear least-squares problem for which we can find the closed-form solution. This is explained in our previous post. However, in this tutorial, we will not use such a solution that is only applicable to linear least-squares problems. Instead, we will use the batch gradient descent (also known as the gradient descent method or the steepest descent method) that is applicable to a much more general class of optimization problems that also includes nonlinear optimization problems and nonlinear least squares problems.
The idea of the batch gradient descent is to approximate the solution of the optimization problem (5) iteratively. Let the optimization variables be grouped inside of the vector  , defined by
, defined by
(6) 
The batch gradient descent method approximates the solution by propagating this iteration
(7) 
where
- The vector of optimization variables at the iteration
 is
is
(8) 
- is the index of the current iteration
 is the step size (learning rate). This is a relatively small real number either selected by the user or selected by using specialized methods, such as line search methods. Here, we assumed that this number is constant and independent from the index of the current iteration. However, this number can also depend on the current iteration.
is the step size (learning rate). This is a relatively small real number either selected by the user or selected by using specialized methods, such as line search methods. Here, we assumed that this number is constant and independent from the index of the current iteration. However, this number can also depend on the current iteration. - The gradient of the cost function
 evaluated at
evaluated at  is denoted by
is denoted by (9)

We propagate the batch gradient descent iteration (7) for  , until convergence of the cost function or optimization vector variables.
, until convergence of the cost function or optimization vector variables.
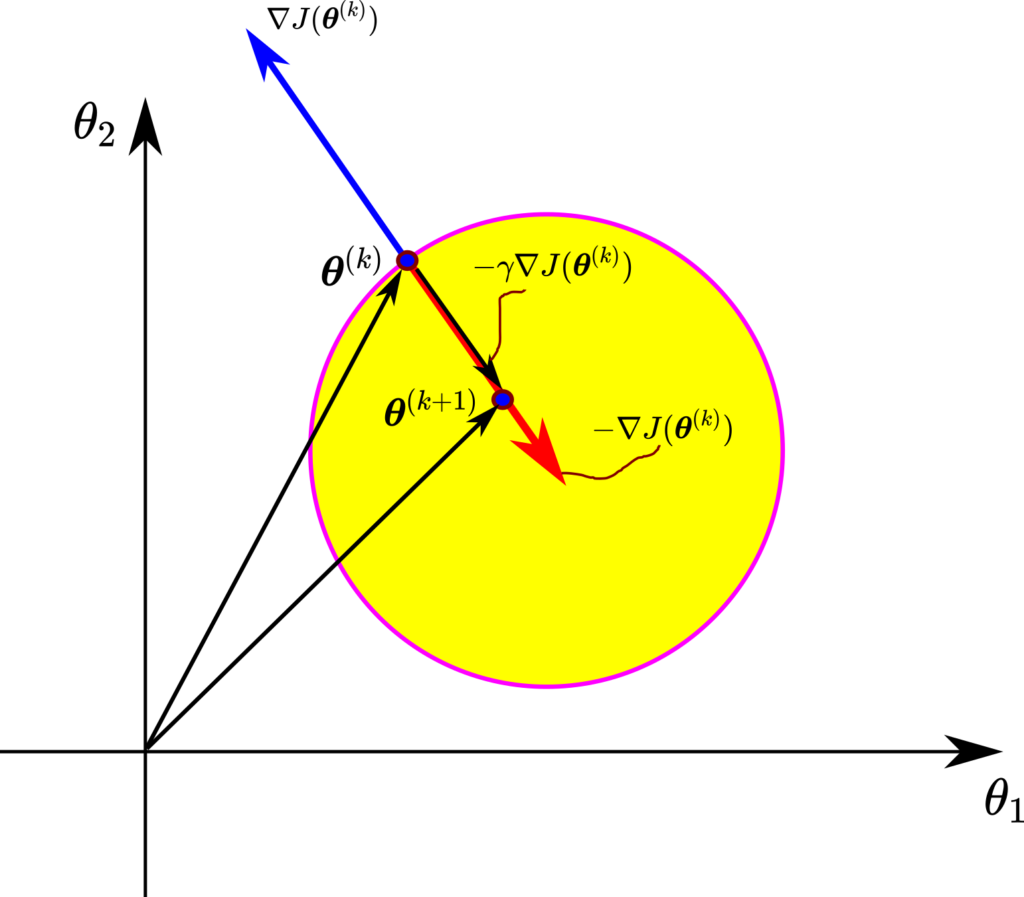
So, what is the physical motivation behind the batch gradient descent method (7)?
Consider the illustration shown after this paragraph. We learned that the gradient vector points to the direction of the fastest increase of a function and is essentially equal to the rate of the fastest increase of the function. Now, if we add a minus sign in front of the gradient, we obtain the opposite direction. In this opposite direction, the decrease of the function will be maximized. If we decrease the function value along this direction starting from the current value of the optimization variable vector , we are doing a good job. That is, we should expect that the cost function will decrease if we move the optimization variable vector in this direction. However, we need to scale our step, so we multiply the negative gradient with a step size that is usually a small number. If we add this negative and scaled gradient to our vector , we get the vector of optimization variables  . The cost function value at the vector should be smaller than the cost function value at the optimization vector . We repeat this procedure iteratively for
. The cost function value at the vector should be smaller than the cost function value at the optimization vector . We repeat this procedure iteratively for  .
.
Let us compute the gradient of the cost function (4), so we can implement the batch gradient descent method in Python. The gradient vector is given by
(10) 
By introducing the error variable
(11) 
By substituting this definition in (10), we have
(12) 
Python Implementation of Batch Gradient Method
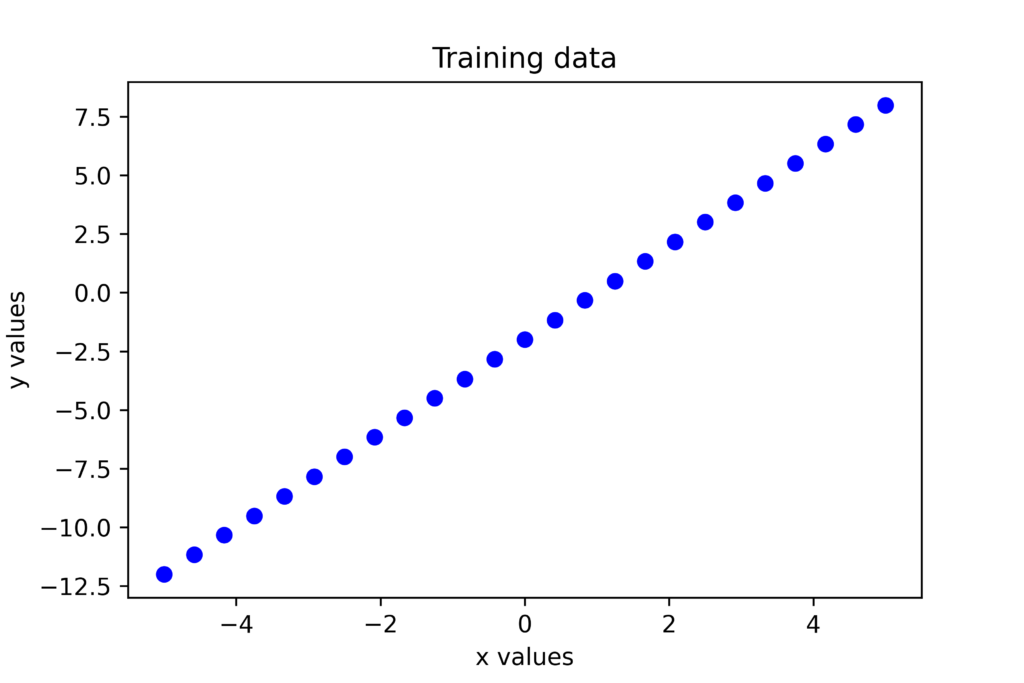
First, we import the necessary libraries and generate the data batch.
# -*- coding: utf-8 -*-
"""
Python implementation of the Batch gradient descent and stochastic gradient descent
"""
import numpy as np
import matplotlib.pyplot as plt
# generate the data
# true value of the parameters that we want to estimate
theta1true=2
theta2true=-2
xValues=np.linspace(-5,5,25)
yValues=np.zeros(xValues.shape)
for i in range(len(xValues)):
# here, change the constant multiplying np.random.normal() to increase/decrease the measurement noise
yValues[i]=theta1true*xValues[i]+theta2true+0.01*np.random.normal()
# plot the data set
plt.plot(xValues,yValues,'bo')
plt.title('Training data')
plt.xlabel('x values')
plt.ylabel('y values')
plt.savefig('dataBatch.png',dpi=600)
plt.show()
We select the true value of the parameters  and
and  .By using this code line:
.By using this code line:
yValues[i]=theta1truexValues[i]+theta2true+0.01np.random.normal()
We generate the vector “yValues”. Also, keep in mind that by adding the term “0.01np.random.normal()” we introduce the measurement noise. Initially, we assume a small value of noise in order to test the convergence of the method. The data that will be used for estimation is shown below.
Next, we define two functions. The first function will return a gradient of the cost function for the data-batch vectors “xValues” and “yValues” and for the current value of the optimization vector . The second function will return the value of the cost function for the current value of the optimization vector and for the data-barch vectors. These functions are given below.
# this function returns the gradient of the cost function
# formed for the data batch vectors x and y, and for the thetaParameterVector
# define the batch gradient function
def gradientBatch(thetaParameterVector, x, y):
gradientBatchValue=np.zeros(shape=(2,1))
gradientTheta1=0
gradientTheta2=0
for j in range(len(x)):
error=(y[j]-thetaParameterVector[0]*x[j]-thetaParameterVector[1])
gradientTheta1=gradientTheta1-2*error*x[j]
gradientTheta2=gradientTheta2-2*error
gradientBatchValue[0]=gradientTheta1
gradientBatchValue[1]=gradientTheta2
return gradientBatchValue
# define the cost function for the current value of the optimization vector
# and for the data batch vectors x and y
def costFunction(thetaParameterVector, x, y):
costFunction=0
for j in range(len(x)):
costFunction=costFunction+(y[j]-thetaParameterVector[0]*x[j]-thetaParameterVector[1])**2
return costFunction
Next, we select the number of iterations of the batch gradient descent method, the step size, and the initial guess of the optimization vector. Then, we define a for loop that implements the batch gradient descent method given by the equation (7). The code lines shown below perform these tasks
# batch gradient descent parameters
# number of iterations
numberIterationsGradient=1000
# step size
stepSizeBatchGradient=0.0001
# initial value of the optimization variables
thetaInitial=np.random.normal(size=(2,1))
# these list store the optimization parameters during iterations
theta1List=[]
theta2List=[]
# this list stores values of the cost function
costFunctionList=[]
# initialize the vector of optimization variables
thetaCurrent=thetaInitial
# here we iteratively update the vector of optimization variables
for i in range(numberIterationsGradient):
theta1List.append(thetaCurrent[0][0])
theta2List.append(thetaCurrent[1][0])
costFunctionList.append(costFunction(thetaCurrent,xValues,yValues))
thetaNext=thetaCurrent-stepSizeBatchGradient*gradientBatch(thetaCurrent,xValues,yValues)
thetaCurrent=thetaNext
print(costFunctionList[i])
The batch gradient descent iteration is implemented in code line 23. We call the previously defined function “gradientBatch” which returns the value of the gradient at the current value of the optimization vector. We also update the list storing the current values of entries of the optimization vector and the current value of the cost function. This is important for investigating the convergence of the method. The figure below shows the convergence of the cost function  with respect to the optimization iteration index .
with respect to the optimization iteration index .
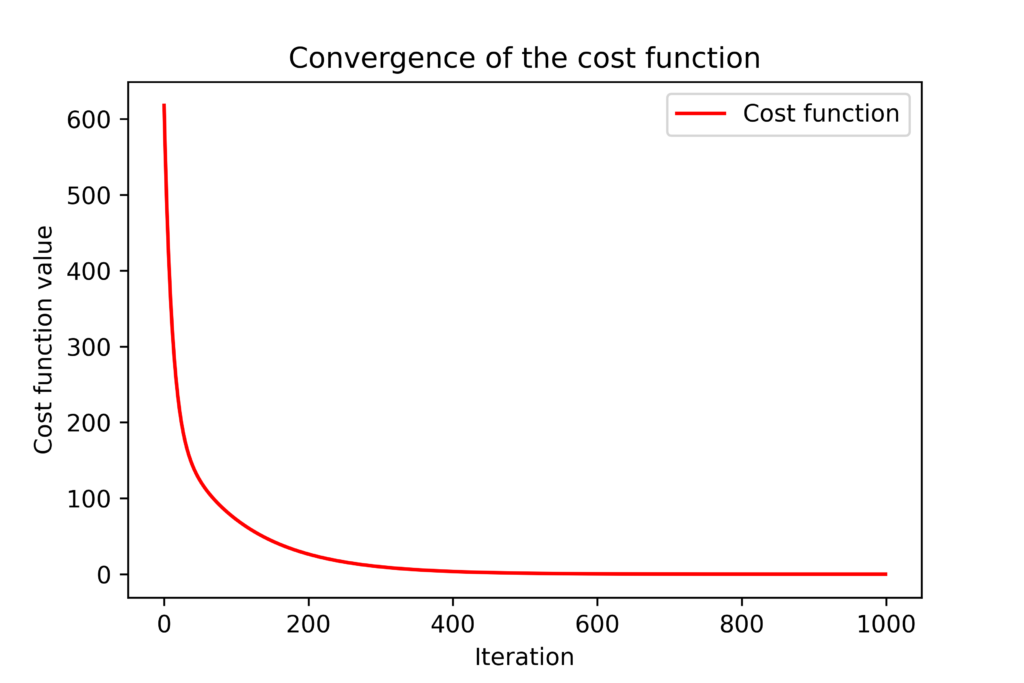 .
.The figure below shows the convergence of the parameters and which are the entries of the optimization vector .
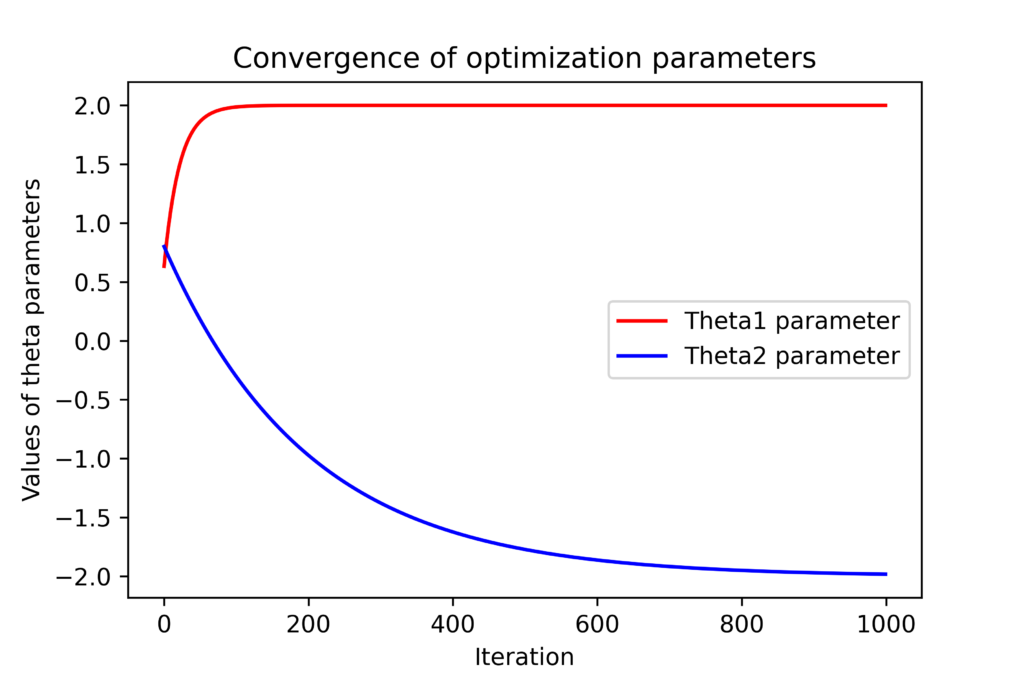 and with respect to the optimization iteration index .4
and with respect to the optimization iteration index .4We can observe that the entries of the optimization vector converge to the true values. However, they will never converge to the exact values due to the introduced measurement noise, unless we have an extremely large number of data samples. The figures shown above are generated by using these code lines.
plt.title('Convergence of the cost function')
plt.plot(costFunctionList,'r',label='Cost function')
plt.xlabel('Iteration')
plt.ylabel('Cost function value')
plt.legend()
plt.savefig('convergenceCostFunction.png',dpi=600)
plt.show()
plt.title('Convergence of optimization parameters')
plt.plot(theta1List,'r',label='Theta1 parameter')
plt.plot(theta2List,'b',label='Theta2 parameter')
plt.xlabel('Iteration')
plt.ylabel('Values of theta parameters')
plt.legend()
plt.savefig('convergenceTheta.png',dpi=600)
plt.show()