 by
by In this tutorial, we explain how to create a simple Large Language Model (LLM) application that can be executed in a web browser. The application is based on Python, Ollama framework for running Llama3.1 LLM, and Stremlit for embedding the application in a web browser and for building a graphics user interface (GUI). The YouTube tutorial is given below.
Here is the workflow and the general idea. The user enters a question through a web browser that runs a Streamlit application. Streamlit directs the question to Llama. Llama computes the answers and sends the answer to Streamlit. Streamlit displays the answer. This is a proof of principle for embedding an LLM in a web application.
This tutorial is based on Llama 3.1 LLM. However, everything explained in this tutorial can be generalized to other LLMs that can be executed through the Ollama framework. The first step is to install Ollama and to download the Llama 3.1 model. To install Ollama, go to this website
select Windows as an operating system, and download the installation file. Execute the installation file and Ollama will be installed. Next, you need to verify the installation. To do that, open a Windows command prompt and type
ollamaIf Ollama is properly installed, the output should look like this

The next step is to download and install the model. To install the model, go to the Llama 3.1 page inside of Ollama by following this link:
https://ollama.com/library/llama3.1
Select the model size (8B) and the installation message will be generated (see the figure below).
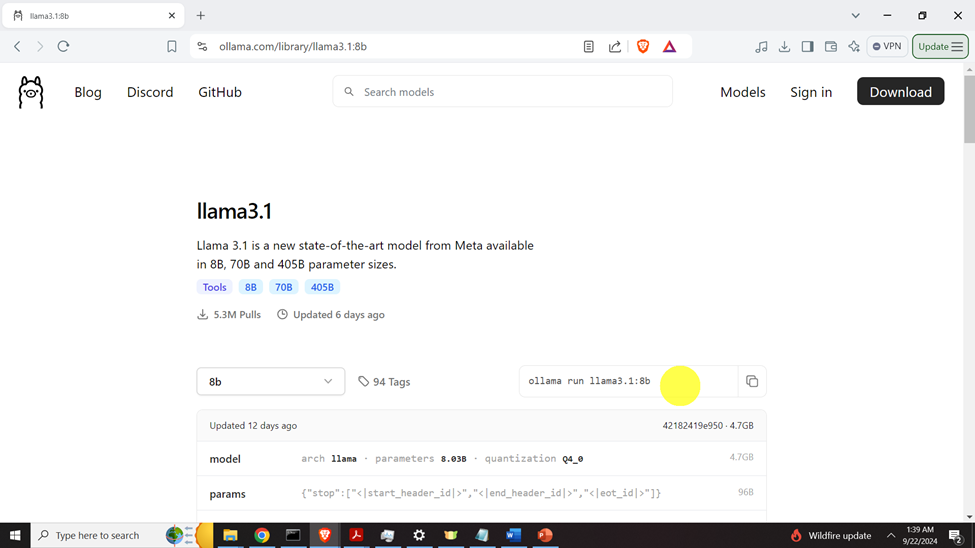
Then, copy and paste this command and execute it in your command prompt.
ollama run llama3.1:8bThis will install the model, and the model will be automatically started. You can ask a question to the model, to make sure that it is working properly. Next, exit the model by typing “/bye”.
The next step is to create our workspace folder, create a Python virtual environment, and install the Python packages. Open a Command Prompt and type
cd\
mkdir codes
cd codes
mkdir testStreamlit
cd testStreamlit
To create a virtual environment
python -m venv env1To activate a virtual environment
env1\Scripts\activate.batInside of the activated virtual environment, Install Ollama and Streamlit Python libraries:
pip install ollama
pip install streamlitNext, create a Python file called “test1.py”. Type this code
# -*- coding: utf-8 -*-
"""
Demonstration on how to create a Large Language Model (LLM) Web Application Using
Streamlit, Ollama, Llama3.1 and Python
Author: Aleksandar Haber
"""
import streamlit as st
import ollama
# set the model
desiredModel='llama3.1:8b'
st.title("Our First LLM Web Application Based on Llama (running locally) and Streamlit")
def generate_response(questionToAsk):
response = ollama.chat(model=desiredModel, messages=[
{
'role': 'user',
'content': questionToAsk,
},
])
st.info(response['message']['content'])
with st.form("my_form"):
text = st.text_area(
"Enter text:",
"Over here, ask a question and press the Submit button. ",
)
submitted = st.form_submit_button("Submit")
if submitted:
generate_response(text)
The st.form() function is used to generate the application. The application is shown below.
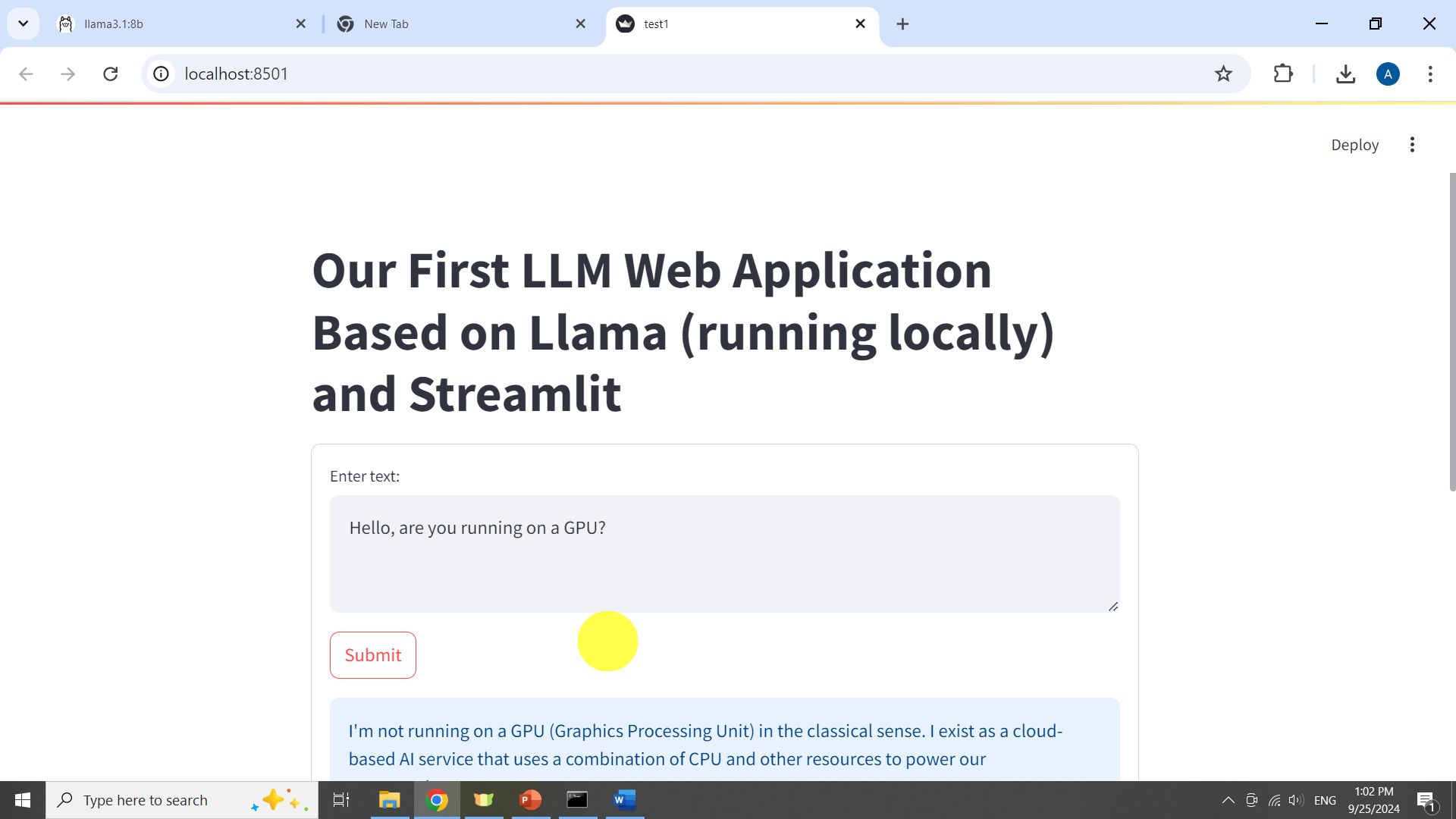
In the prompt “Enter text” the user enters a question to the LLM. Once the Submit button is pressed, the question in the form of a string is passed to the LLM. This is done by calling st.form_submit_button(“Submit”) and by calling generate_response(text). Then, the function “generate_response()” is executed. This function passes the question to Ollama which passes the question to Llama. Once the question is generated, it is displayed in the Web App. Simple as that!