 by
by In this tutorial, we explain how to download and run an unofficial release of Microsoft’s Phi 4 Large Language Model (LLM) on a local computer.
- Phi 4 is a 14B parameter state-of-the-art small LLM that is especially tuned for complex mathematical reasoning.
- According to the information found online, the model is downloaded from the Azure AI foundry and converted to the GGUF format. The GPT-Generated Unified Format (GGUF) is a binary format that is optimized for quick loading and saving of models which makes it attractive for inference purposes. It has a reduced memory footprint, relatively quick loading times, and is optimized for lower-end hardware.
- We will download and use the Phi 4 LLM by using Ollama. Ollama is an easy-to-use command line framework for running various LLM on local computers. It is a good strategy to first test LLMs by using Ollama, and then to use them in Python or some other programming language.
- Our computer has NVIDIA 3090 GPU with 24 GB RAM and Intel i9 processor with 48 GB regular RAM memory.
The YouTube tutorial is given below.
The first step is to install Ollama. Go to the official Ollama website:
https://www.ollama.com/download/windows
and click on the Download link to download the Ollama installation file.
Then, to verify the installation, open a Windows Command Prompt and type
ollama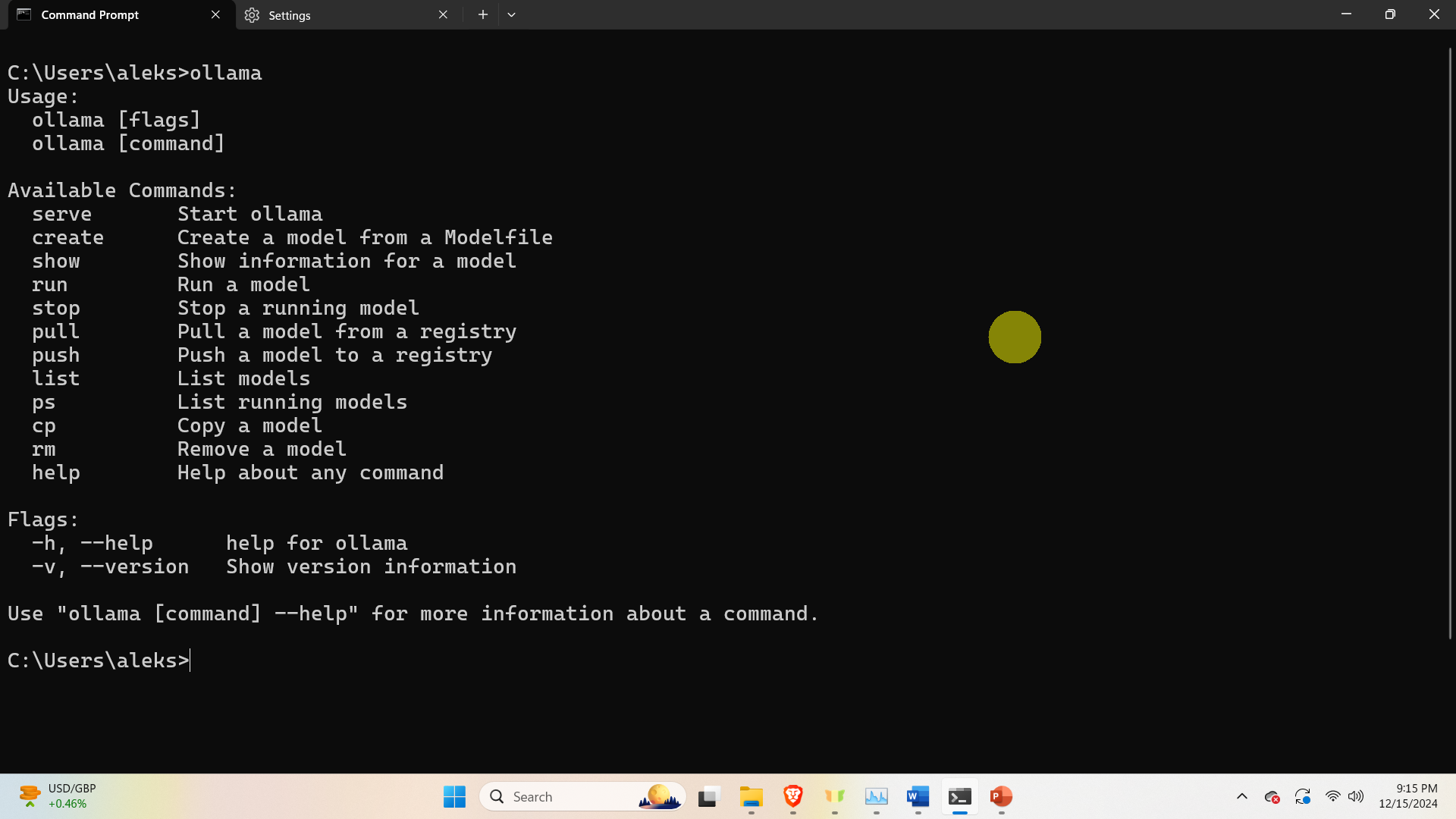
Next, we need to Download the Phi 4 model. Go to the website:
https://ollama.com/vanilj/Phi-4/tags
and search for the appropriate model
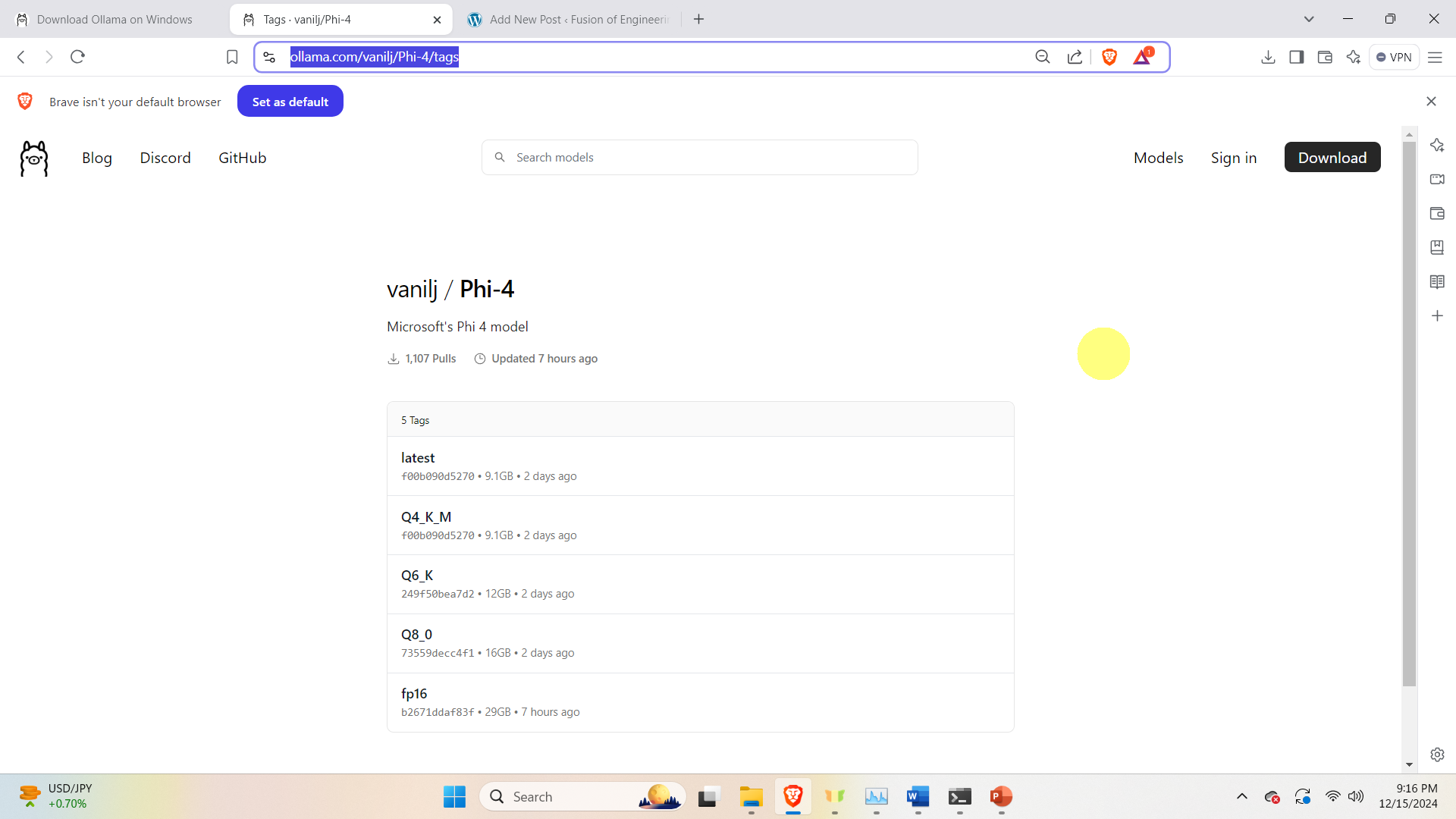
The figure above shows all the available models. Let us select the Q8_0 model. Click on this model, and copy the command for downloading and running the model
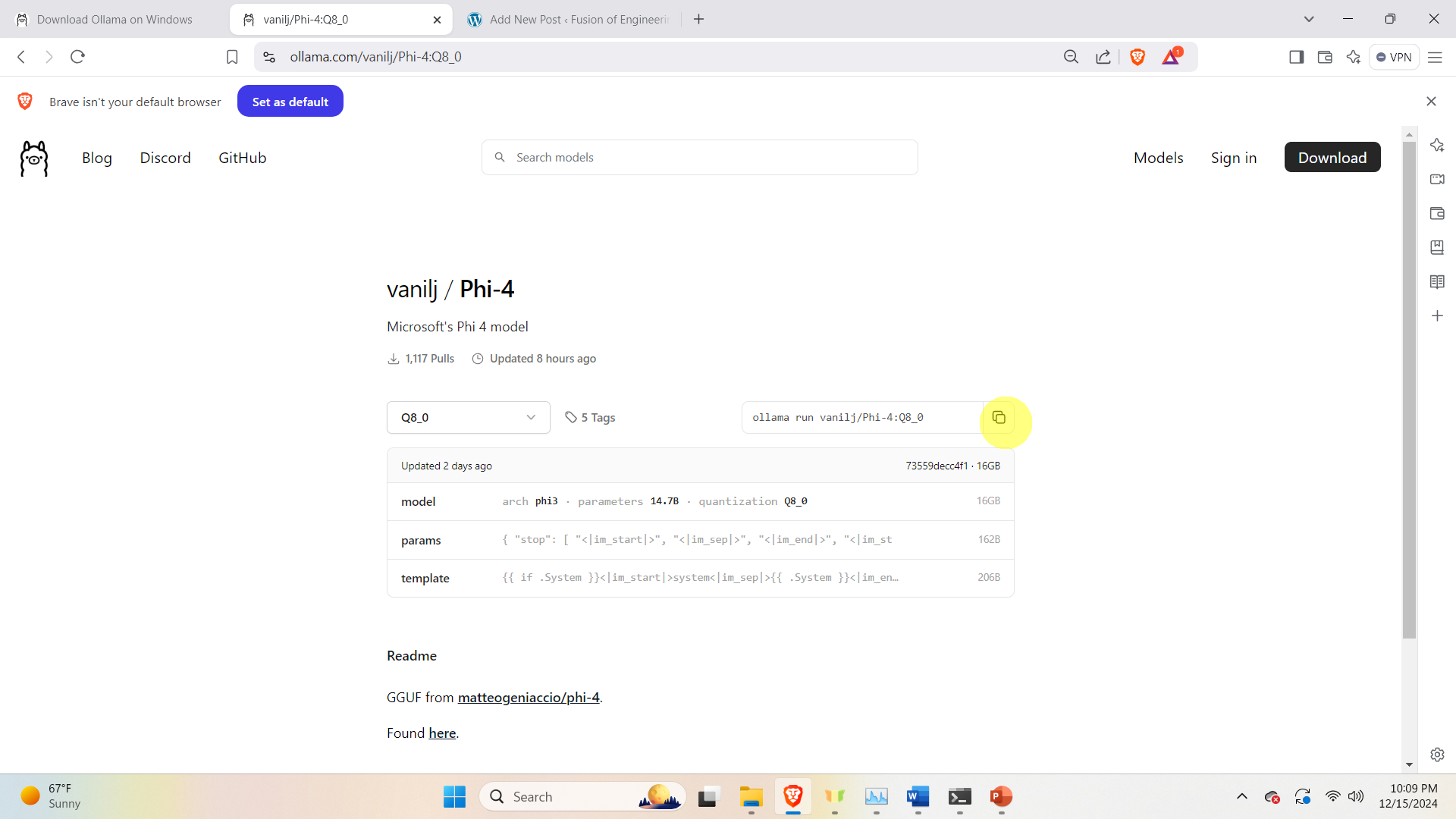
Next, open a Windows Command Prompt and paste the command:
ollama run vanilj/Phi-4:Q8_0This command will download and run the model in Ollama.