 by
by What is covered in this tutorial: In this machine learning and large language model (LL) tutorial, we explain how to install and run a quantized version of DeepSeek-V3 on a local computer with GPU and on Linux Ubuntu. To properly run and install DeepSeek-V3, we will build a Llama.cpp program from a source with CUDA GPU support. We use Llama.cpp since this program enables us to run different types of LLMs with minimal setup time.
Motivation: DeepSeek-V3 is a powerful Mixture-of-Experts (MoE) language model. According to the test data published by people behind DeepSeek-V3, this model outperforms Qwen2.5-72B, Llama 3.1-405B, GPT-4o-0513 and Claude-3.5-Sonnet. Consequently, it is important to test the performance of DeepSeek-V3 and potentially integrate it into your project.
The YouTube tutorial is given below.
Prerequisites
We tested a quantized version of DeepSeek-V3 on a computer with the following specs:
- NVIDIA 3090GPU (24 GB VRAM)
- 64 GB RAM
- Intel i9 processor
- You need Ubuntu 22.04 or Ubuntu 24.04
– You will need around 220GB of free space to download the smallest model (Q2). You also need to install the CUDA Toolkit and NVCC compiler in order to build llama.cpp from source. This will be explained later on in this tutorial.
Installation Instructions
The first step is to install the NVIDIA CUDA Toolkit and the NVCC compiler. To do that, go to the official NVIDIA website:
https://developer.nvidia.com/cuda-toolkit
and generate the installation instructions for the NVIDIA CUDA Tookit, as shown in the figure below.
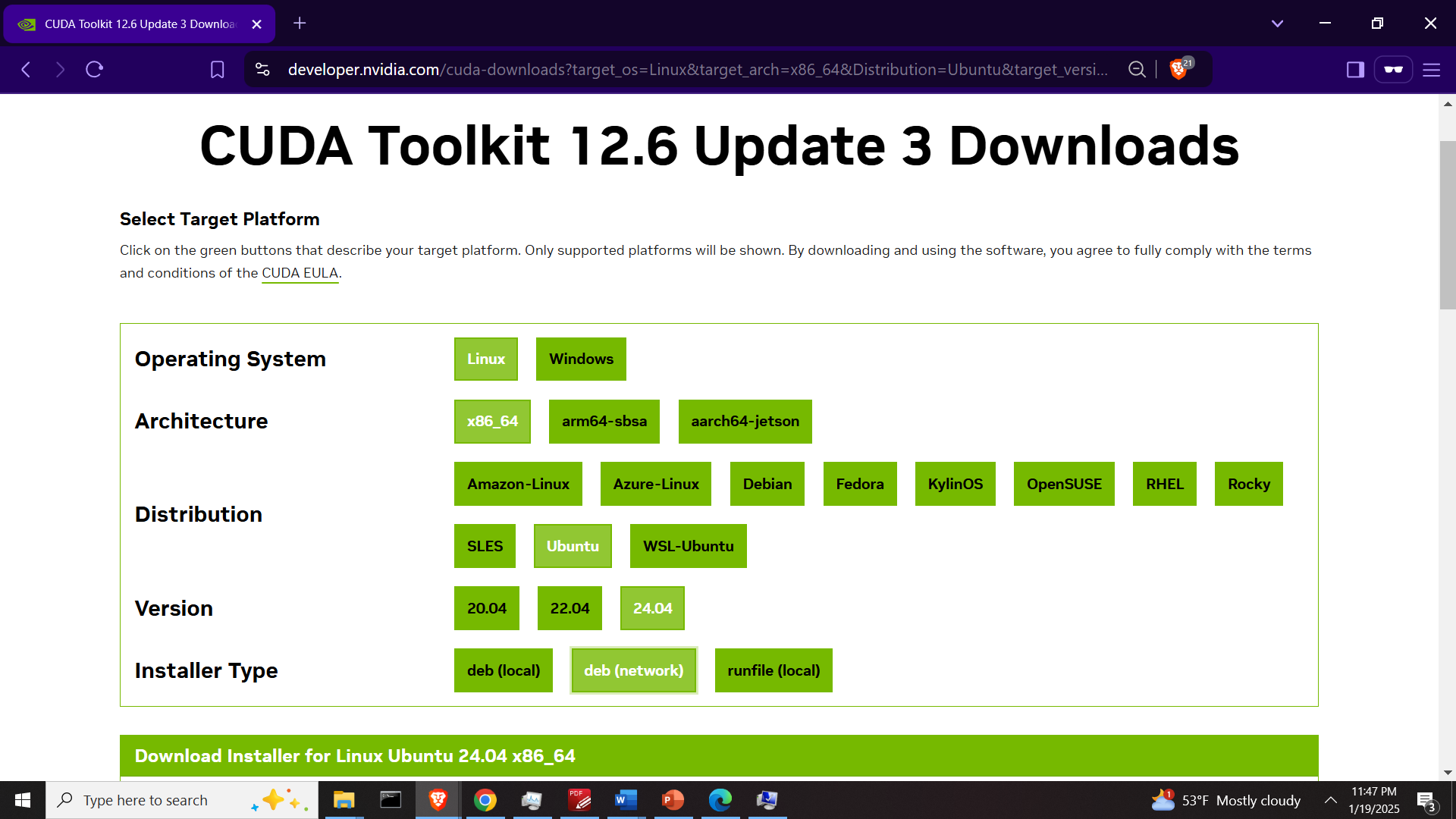
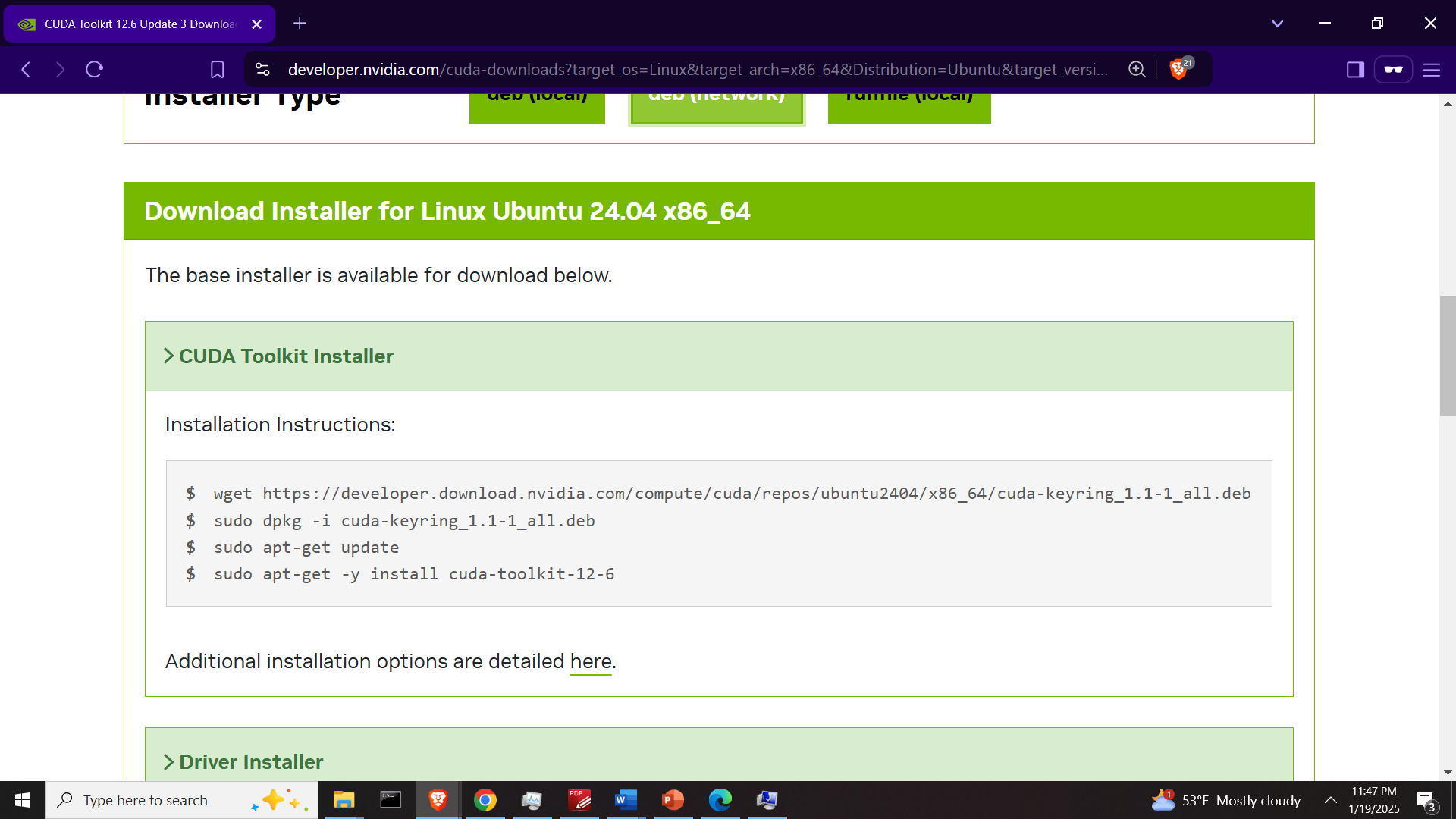
Open a Linux Ubuntu terminal and run the generated commands
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-6After that, we need to add the CUDA toolkit binary files (executable files) to the system path. The CUDA binary folder is located at
/usr/local/cuda-12.6/binTo add this folder to the bath, you need to edit .bashrc file in the home folder:
cd ~
sudo nano and add the following line at the end of the file
export PATH=/usr/local/cuda-12.6/bin${PATH:+:${PATH}}Save the file and restart the terminal. Next, open a terminal and type
nvcc --versionYou should get a reply if everything is properly installed.
Next, install Git
sudo apt install git-allNext, go to the home folder, clone the remote Llama.cpp repository and change the current folder to the cloned folder called llama.cpp
cd ~
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Then, build the project
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j $(nproc)
Then, download the DeepSeek model files. For that purpose go to the Huggingface website
https://huggingface.co/unsloth/DeepSeek-V3-GGUF
and click on the desired model, and download all 5 model files. In our case, we select the model Q2_K_XS and download the files
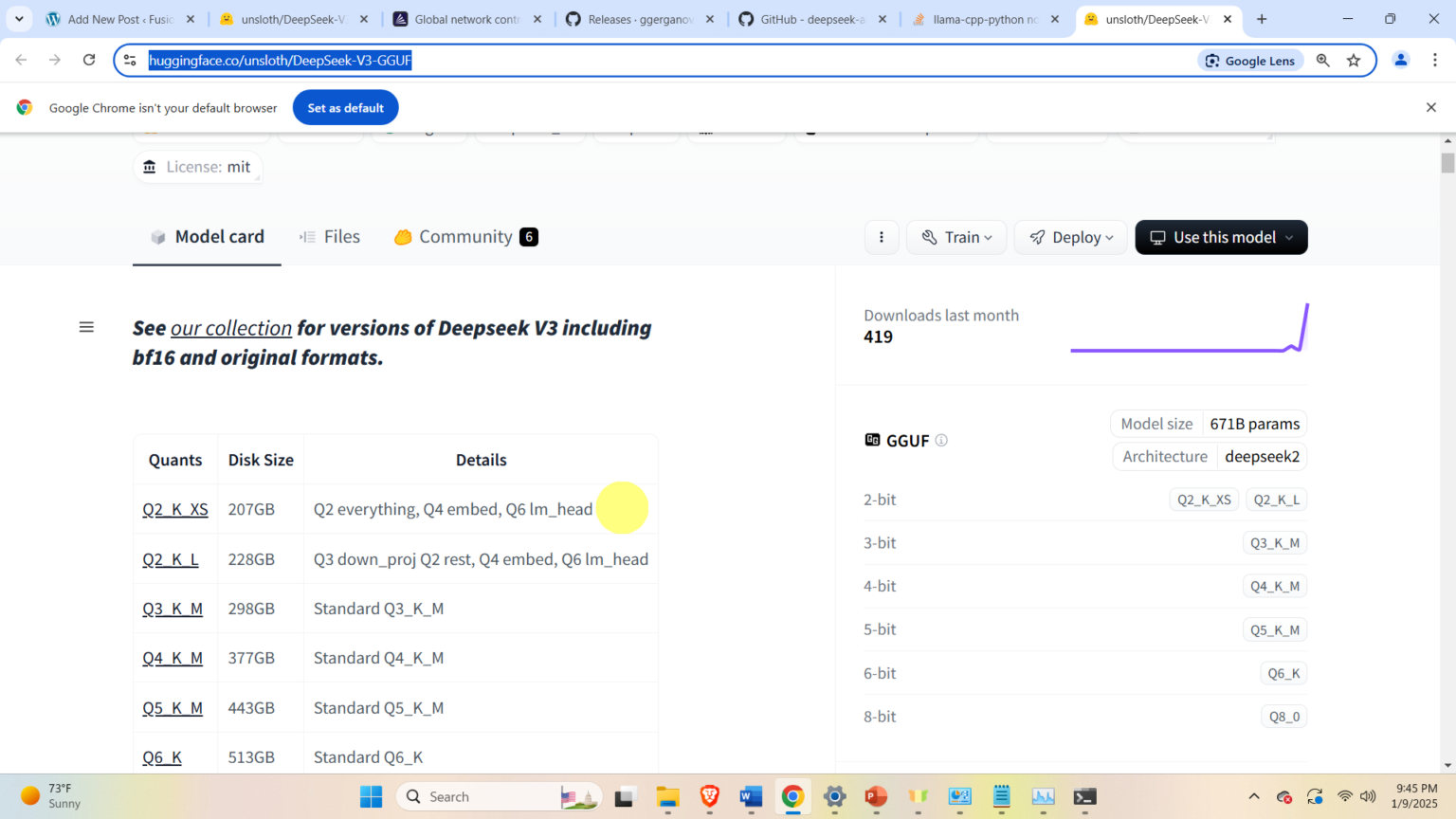
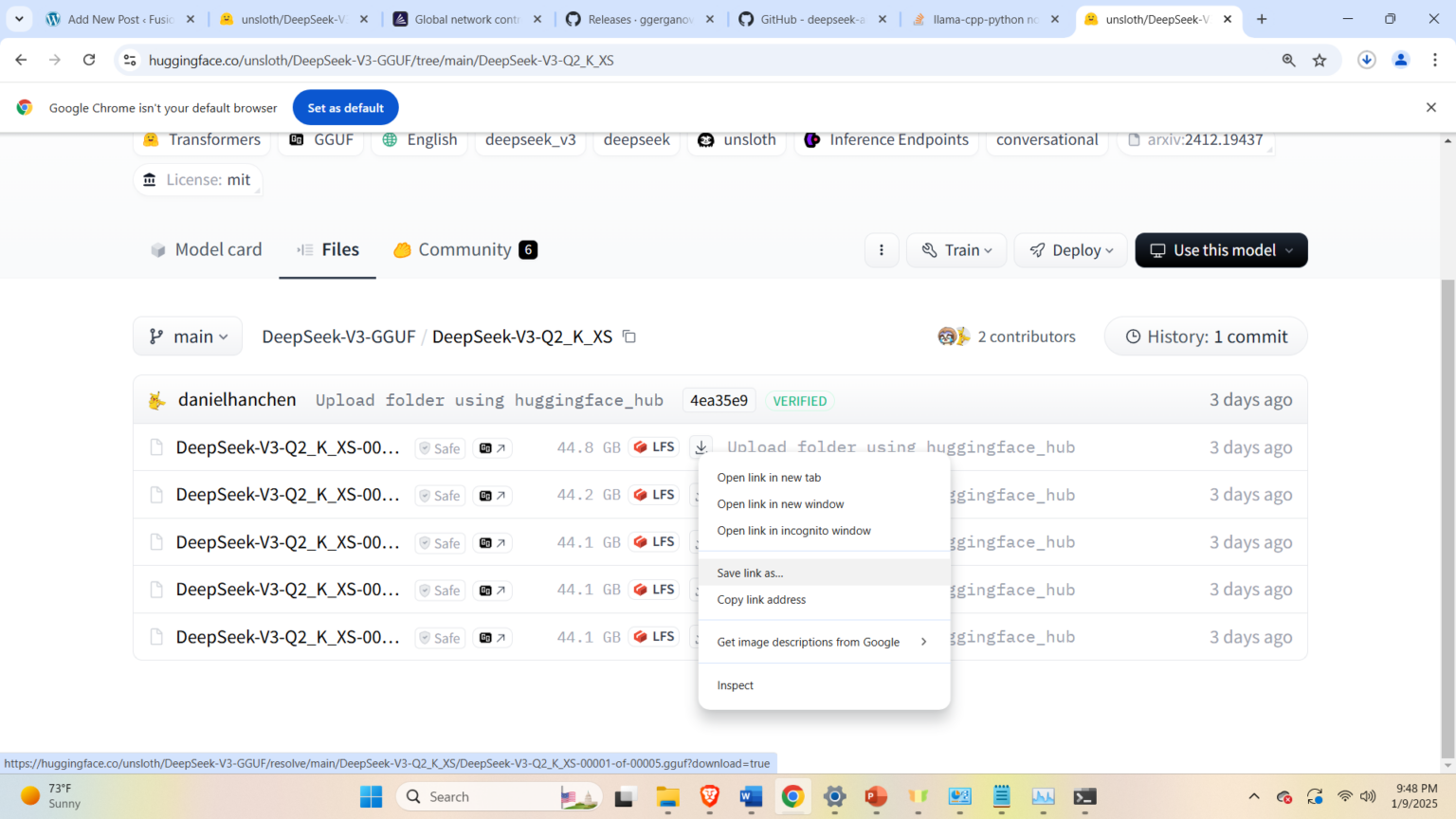
After the files are downloaded, copy them to the folder
~/llama.cpp/build/binAfter that, navigate to this folder
cd ~/llama.cpp/build/binand run the model by typing
./llama-cli --model DeepSeek-V3-Q2_K_XS-00001-of-00005.ggufThis will run the model in the interactive mode.