 by
by – In this tutorial, we explain how to install and run Llama 3.3 70B LLM in Python on a local computer. Llama 3.3 70B model offers similar performance compared to the older Llama 3.1 405B model. However, the Llama 3.3 70B model is smaller, and it can run on computers with lower-end hardware. Our local computer has NVIDIA 3090 GPU with 24 GB RAM. The computer has 48 GB RAM and the Intel CPU i9-10850K. Llama 3.3 works on this computer, however, the inference speed is not fast. We can speed up the inference by changing model parameters. More about this in the future tutorials.
In this tutorial we will explain how to install and run a quantized Llama3.3 model. The model is denoted by
70b-instruct-q2_K. To install this highly quantized model you will need 26GB disk space. You can also try to install the regular model. For the regular model you will need 40GB disk space.
– The installation procedure is:
1) Install Ollama on a local computer. Ollama is a framework and software for running LLMs on local computers. By using Ollama, you can use a command line to start a model and to ask questions to LLMs.
2) Once we install Ollama, we will manually download and run Llama 3.3 70B model.
3) Create a Python virtual environment, install Ollama Python library, and run a Python script.
The YouTube tutorial is given below.
Download and Install Ollama
Go to the Ollama website
and click on Download to download Ollama.
Then, install Ollama by opening the Downloaded file.
Next, open Command Prompt and type
ollamaIf Ollama is properly installed, the output should look like this
Download and Test Llama 3.3 70B model.
The next step is to download the model. Go to the Llama model webpage
https://ollama.com/library/llama3.3/tags
and search for an appropriate model. In our case, we will select 70b-instruct-q2_K model. We select this model since it requires the smaller disk space.
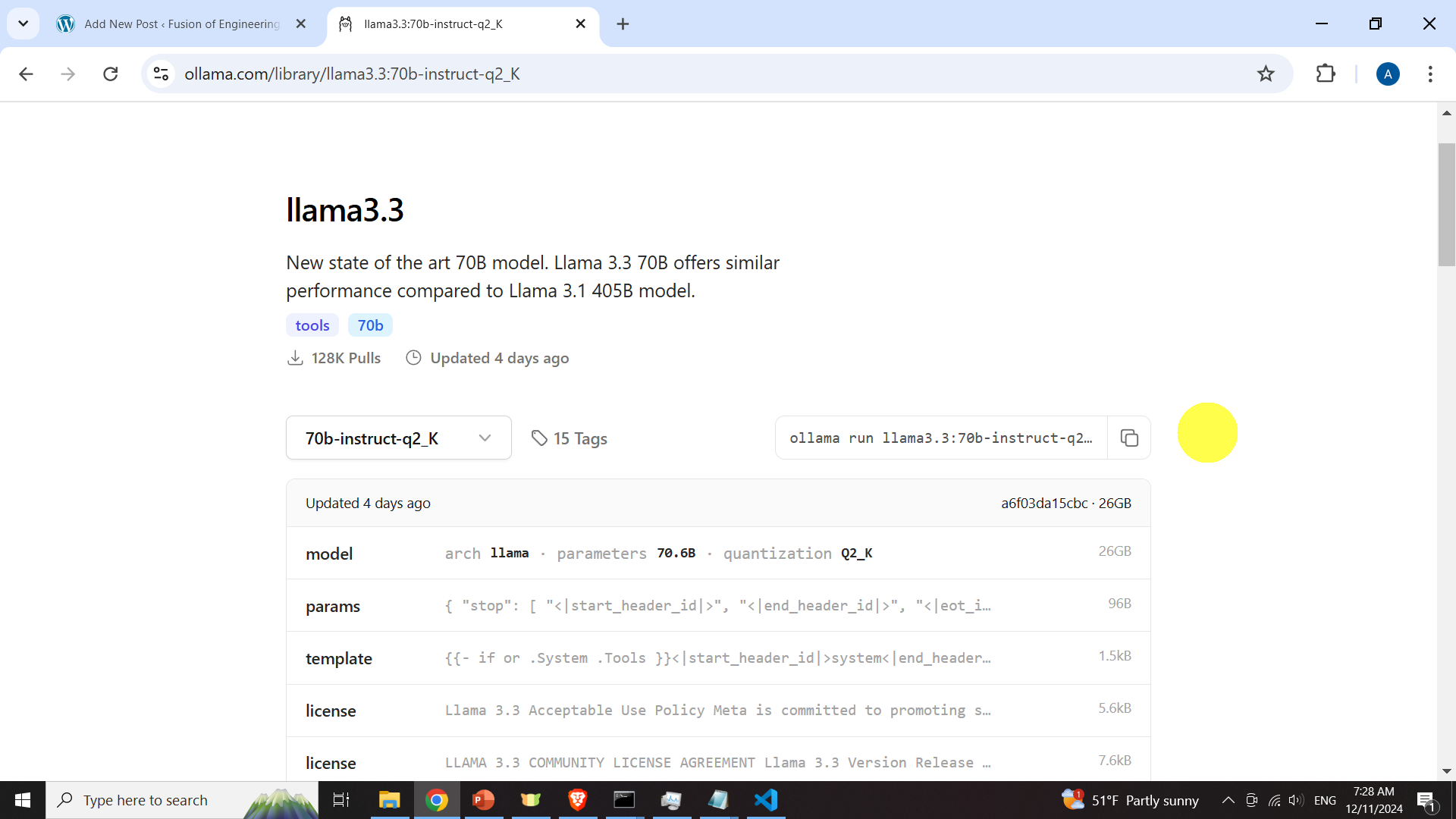
Next, to download the model, open a terminal and type
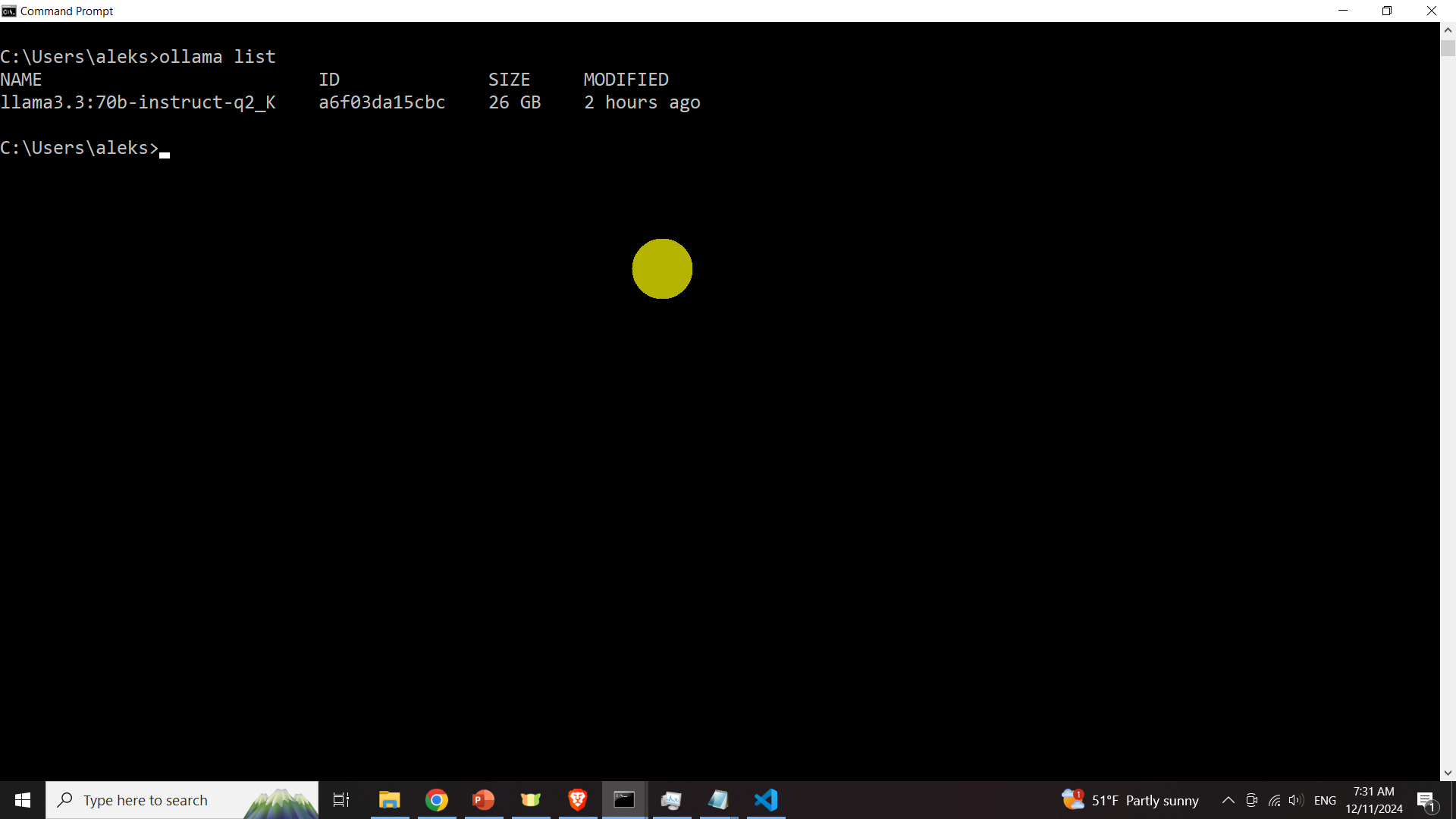
ollama pull llama3.3:70b-instruct-q2_KAfter the model is downloaded, type
ollama listto list the model
Next, we need to check that the model is installed and that can be executed. To do that, open a terminal and type
ollama run llama3.3:70b-instruct-q2_Kand type a question to test the model
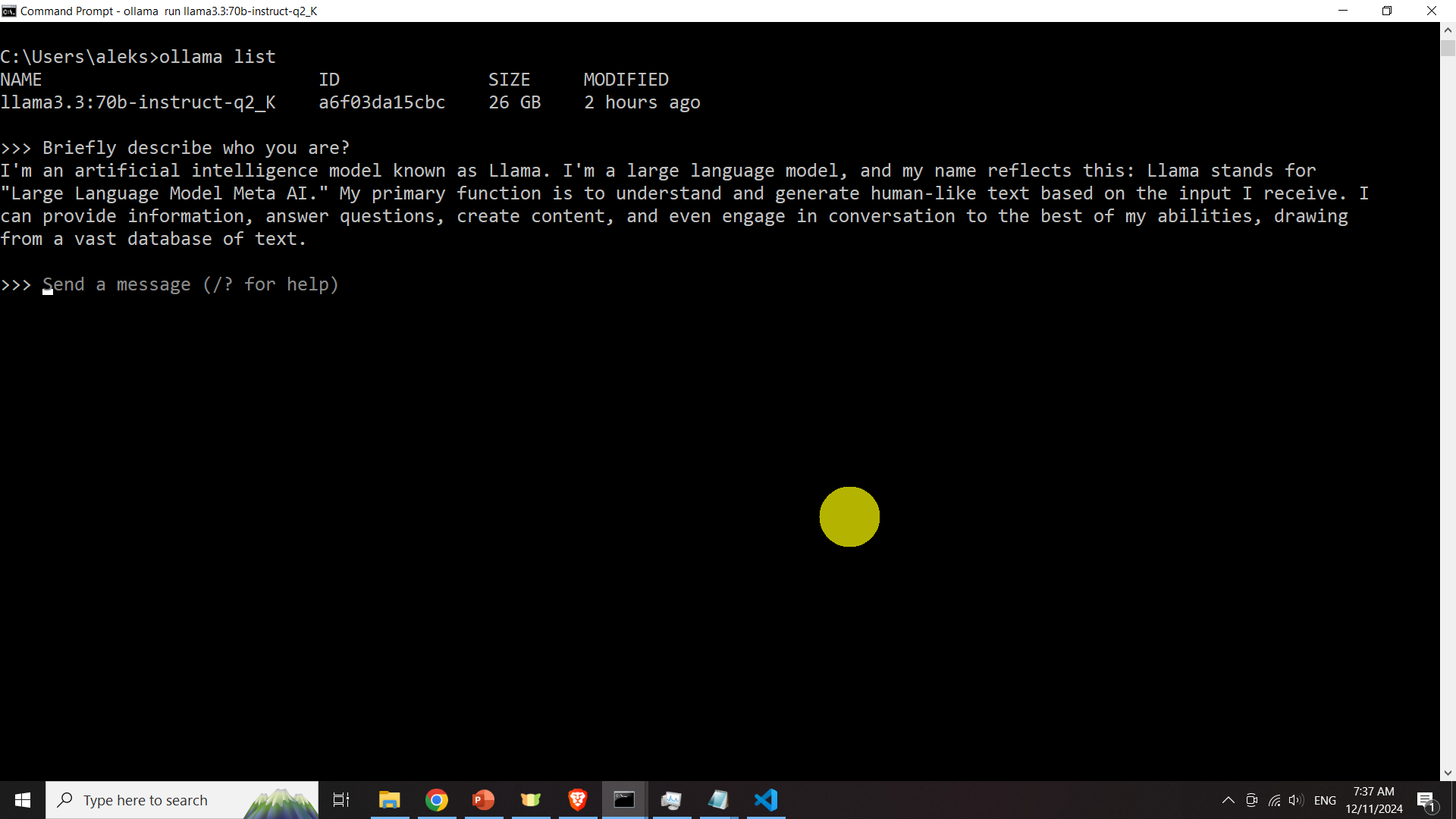
Next, exit the model by entering CTRL+d
Run LLama 3.3 70B Model in Python
First, we create a workspace folder and a Python virtual environment. Open a Command Prompt and type
cd\
mkdir codes
cd codes
mkdir ollamaTest
cd ollamaTest
python -m venv ollama
ollama\Scripts\activate.batNext, we need to install the Ollama Python library:
pip install ollamaThe next step is to write a Python script. The script is given below.
import ollama
desiredModel='llama3.3:70b-instruct-q2_K'
questionToAsk='How to solve a quadratic equation. Generate your response by using a maximum of 5 sentences.'
response = ollama.chat(model=desiredModel, messages=[
{
'role': 'user',
'content': questionToAsk,
},
])
OllamaResponse=response['message']['content']
print(OllamaResponse)
with open("OutputOllama.txt", "w", encoding="utf-8") as text_file:
text_file.write(OllamaResponse)This script will load the model, ask the question:
How to solve a quadratic equation. Generate your response by using a maximum of 5 sentences.and run the model. The response will be printed on the computer screen and it will also written to the file called “OutputOllama.txt”. The response is given below.
To solve a quadratic equation, start by writing the equation in the standard form: ax^2 + bx + c = 0. The next step is to use the quadratic formula: x = (-b ± √(b^2 - 4ac)) / (2a). Plug in the values of a, b, and c into the formula to find the solutions. Simplify the expression to get the two possible values of x. If the equation has real roots, these values will be the solutions to the quadratic equation.