 by
by In this tutorial, we explain how to install and run Llama 3.2 1B and 3B models in Python by Using Ollama. Llama 3.2 is the newest family of large language models (LLMs) published by Meta. Llama 3.2 1B and 3B models are light-weight text-only models. They are significantly smaller than similar models in the Lamma 3.1 family of models. Consequently, they are more suitable for running on computers with limited computational resources.
There are several approaches to running Llama 3.2 models in Python. The first approach is to install and run them by downloading them from the Huggingface repository. The second approach, that we explain in this tutorial, is to install and run them by using the Ollama framework. In the follow-up tutorial we will explain how to install and run Llama 3.2 1B and 3B models in Python by using the Huggingface repository.
The YouTube video tutorial is given below.
Install Ollama and Llama 3.2 1B and 3B Models
First, we need to install Ollama and Llama 3.2 1B and 3B models. Download and install Ollama
Go to: https://ollama.com/download
and download the Windows installer of Ollama.
Then install Ollama. After the installation, Ollama will be running in the background. Then open a Command Prompt and type:
ollama The output should look like this
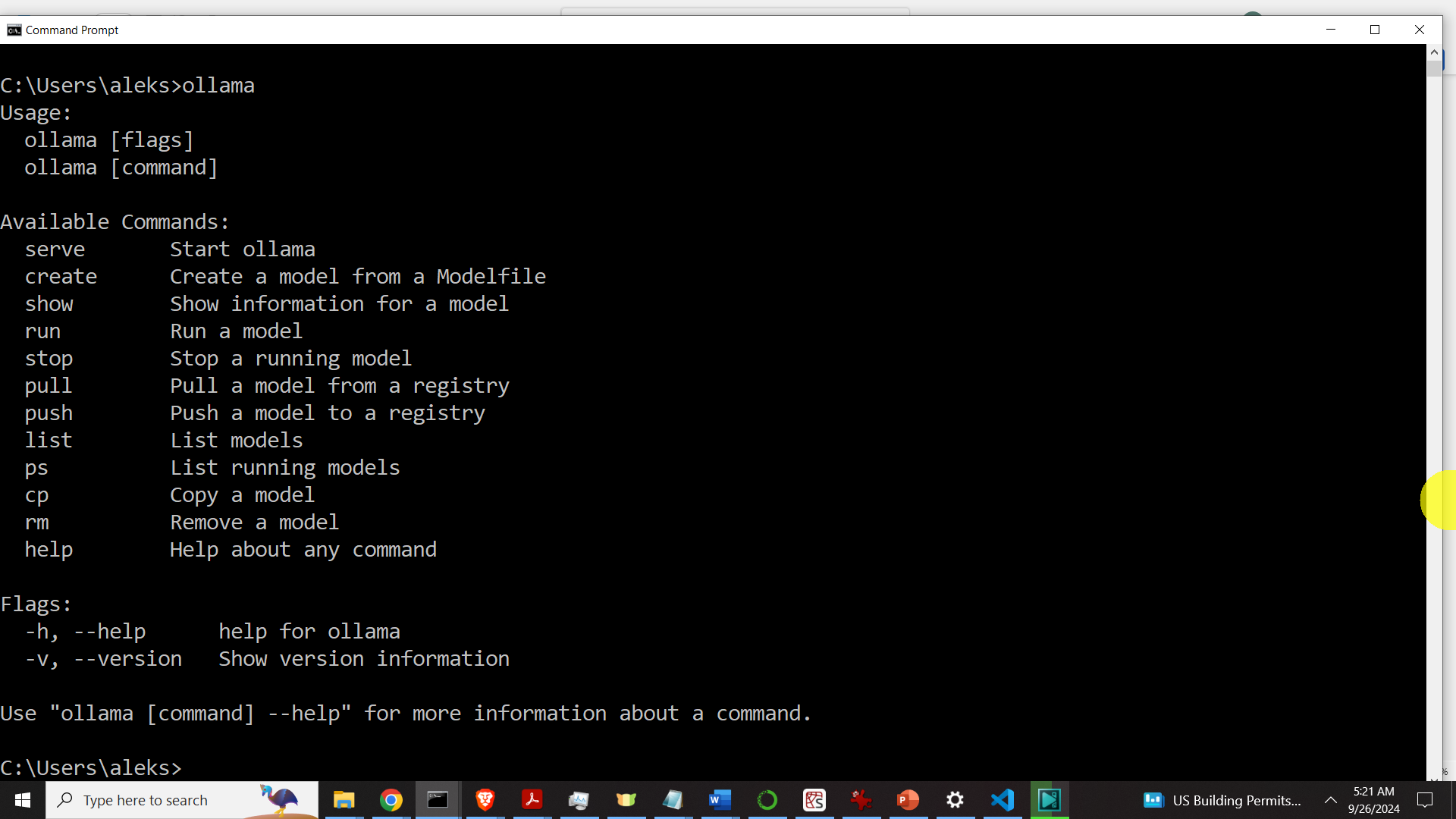
if you see such an output, this means that Ollama is properly installed on your system. The next step is to install the models. To install the model, go to the Llama 3.2 page inside of Ollama:
https://ollama.com/library/llama3.2
Select the models, and copy the installation commands.
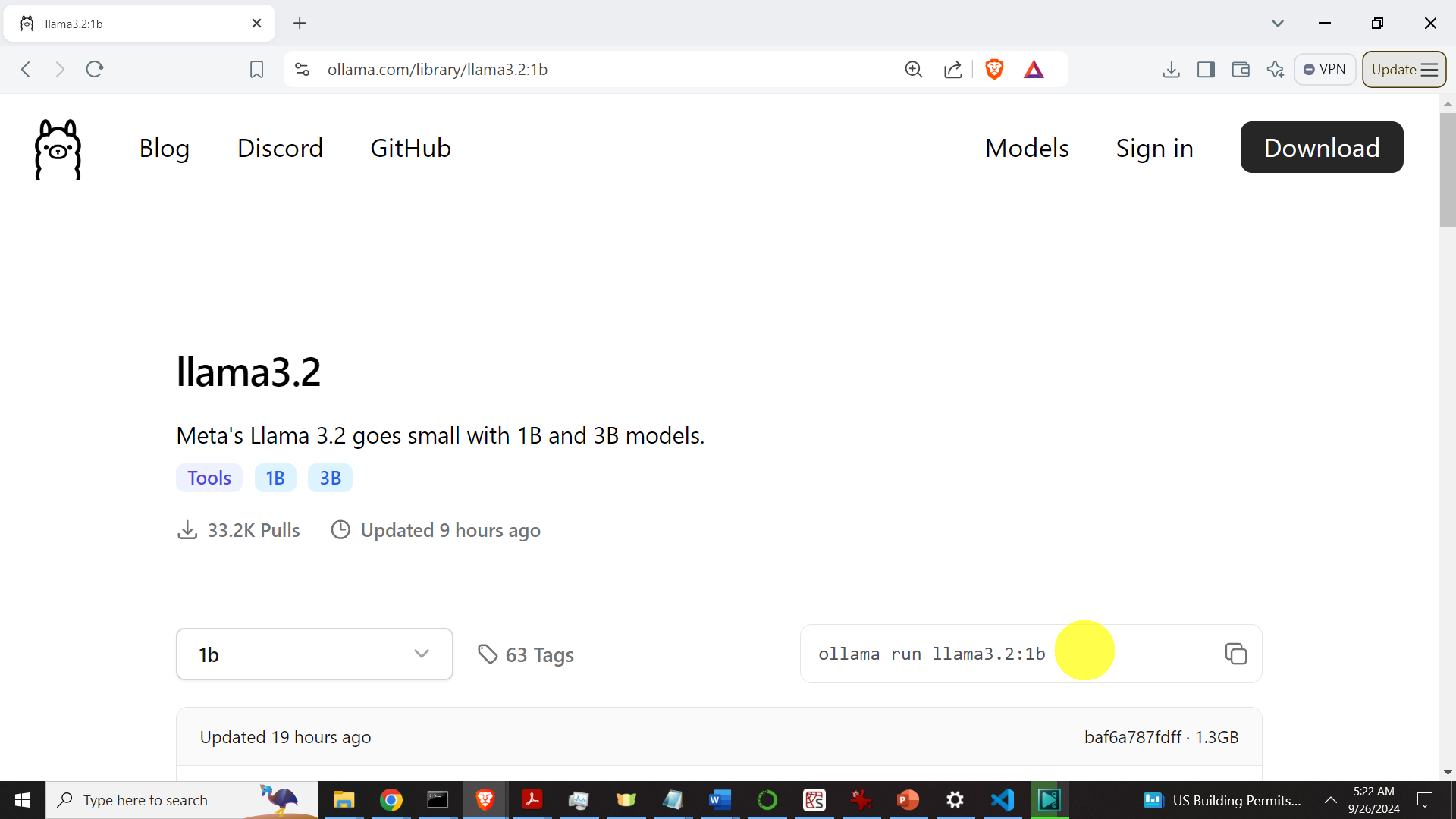
In the installation commands replace “run” by “pull” since we only want to download the models and not to immediately run them. The commands should look like this
ollama pull llama3.2:1b
ollama pull llama3.2:3b
Execute them in a Windows command prompt. Then, type
ollama listand you should see the models:
llama3.2:3b a80c4f17acd5 2.0 GB 3 minutes ago
llama3.2:1b baf6a787fdff 1.3 GB 5 minutes ago
Next, let us test these models by running them:
ollama run llama3.2:3b This should run the model. Ask a question to see if it works and then type “/bye” to exit. Then, run the second model
ollama run llama3.2:1b and repeat the same procedure as in the case of the first model.
Create Workspace Folder, Create Python Virtual Environment, and Install Ollama Python Library
The next step is to create a workspace folder, create a Python virtual environment, and install the necessary packages. Open a Windows Command Prompt and type
cd\
mkdir codes
cd codes
mkdir testLlama
cd testLlama
Create a virtual environment:
python -m venv env1Activate virtual environment
env1\Scripts\activate.batInstall Ollama Python API
pip install ollamaRun Llama 3.2 in Python Using Ollama Library
The code that runs Llama 3.2 model in Python using the Ollama library is given below. The code is self-explanatory. The main thing is to precisely type the model name. The model name should be specified in the string “desiredModel”. This model name should perfectly match the model name obtained by typing “ollama list”.
import ollama
desiredModel='llama3.2:3b'
questionToAsk='What is the best strategy to learn coding?'
response = ollama.chat(model=desiredModel, messages=[
{
'role': 'user',
'content': questionToAsk,
},
])
OllamaResponse=response['message']['content']
print(OllamaResponse)
with open("OutputOllama.txt", "w", encoding="utf-8") as text_file:
text_file.write(OllamaResponse)