In this mathematics and statistics tutorial, we explain one very important technique for approximating expectations and integrals of functions. This technique is based on the Monte Carlo Method. It is used in a large number of applications, such as simulation of random processes, state estimation of dynamical systems, machine learning, etc. For us, the most interesting application is state estimation of dynamical systems by using particle filters. Namely, the Monte Carlo method is the basis for the importance sampling method that serves as the basis of particle filters. The importance sampling is explained in the tutorial given here. In this tutorial, all the theoretical concepts are illustrated by using Python examples. The YouTube video accompanying this tutorial is given below.

Before we explain the main idea of the Monte Carlo method, we need to explain that this method is not only restricted to the approximation of expectations and integrals involving functions of random variables. As we explain in this tutorial, this method can also be used to approximate integrals of functions of deterministic variables.
Basic Idea of the Monte Carlo Method – Intro Example
Let us first consider a simple example. Let us say that we want to compute an expectation of a random scalar variable X with the probability density function 
![x\in [a,b]](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-bd6f11c02700ab2b5c13ea6f0b1986fb_l3.png "Rendered by QuickLaTeX.com")






(1) ![\begin{align*}\mathbb{E}[X]=\int_{a}^{b}xf(x)\text{d}x\end{align*}](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-49763f93d32c77e61b45d9256c79aad3_l3.png "Rendered by QuickLaTeX.com")

where ![\mathbb{E}[X]](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-ccb0f5ca44615f175e81d08f9cd86413_l3.png "Rendered by QuickLaTeX.com")



Knowing the mathematical form of the probability density function
The Monte Carlo method solves this problem in this way:
- Draw


- Approximate the expectation by the following average:
(2)

where



The equation (2) is called the Monte Carlo estimator of the expectation. From the law of large numbers, it follows that this estimator is a consistent estimator of expectation. Also, this estimator is unbiased. This means that
- As
- For finite values of
(3)
![\begin{align*}\mathbb{E}\big[ \hat{E}_{N} \big] =\mathbb{E}[X]\end{align*}](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-d62e1449c3a3a9625a02051af7c8778f_l3.png "Rendered by QuickLaTeX.com")

Here it should be kept in mind that every time we draw
Before we generalize the Monte Carlo method to more complex functions and examples, let us now test this important method.
First, let us create a normal distribution in Python with a given mean and standard deviation. In our previous tutorial, given here and here, we explained how to construct a normal distribution in Python and how to draw samples from the normal distribution. By using these ideas, we construct a normal distribution in Python:
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# define a normal distribution in Python:
# mean value
meanValue=15
# standard deviation
standardDeviation=5
# create a normal distribution
# the keyword "loc" is used to specify the mean
# the keyword "scale" is used to specify the standard deviation
distribution=stats.norm(loc=meanValue, scale=standardDeviation)
# plot the probability density function of the distribution
# start point
startPointXaxis=distribution.ppf(0.01)
# end point
endPointXaxis=distribution.ppf(0.99)
# create the x values
xValue = np.linspace(startPointXaxis,endPointXaxis, 500)
# the function pdf() will return the probability density function values
yValue = distribution.pdf(xValue)
# plot the probability density function
plt.figure(figsize=(8,6))
plt.gca()
plt.plot(xValue,yValue, color='blue',linewidth=4)
plt.fill_between(xValue, yValue, alpha=0.2)
plt.title('Normal Distribution', fontsize=14)
plt.xlabel('x', fontsize=14)
plt.ylabel('pdf(x)',fontsize=14)
plt.tick_params(axis='both',which='major',labelsize=14)
plt.grid(visible=True)
plt.xlim((startPointXaxis,endPointXaxis))
plt.ylim((0,max(yValue)+0.005))
plt.savefig('normalDistribution2.png',dpi=600)
plt.show()
The distribution is shown in the figure below.

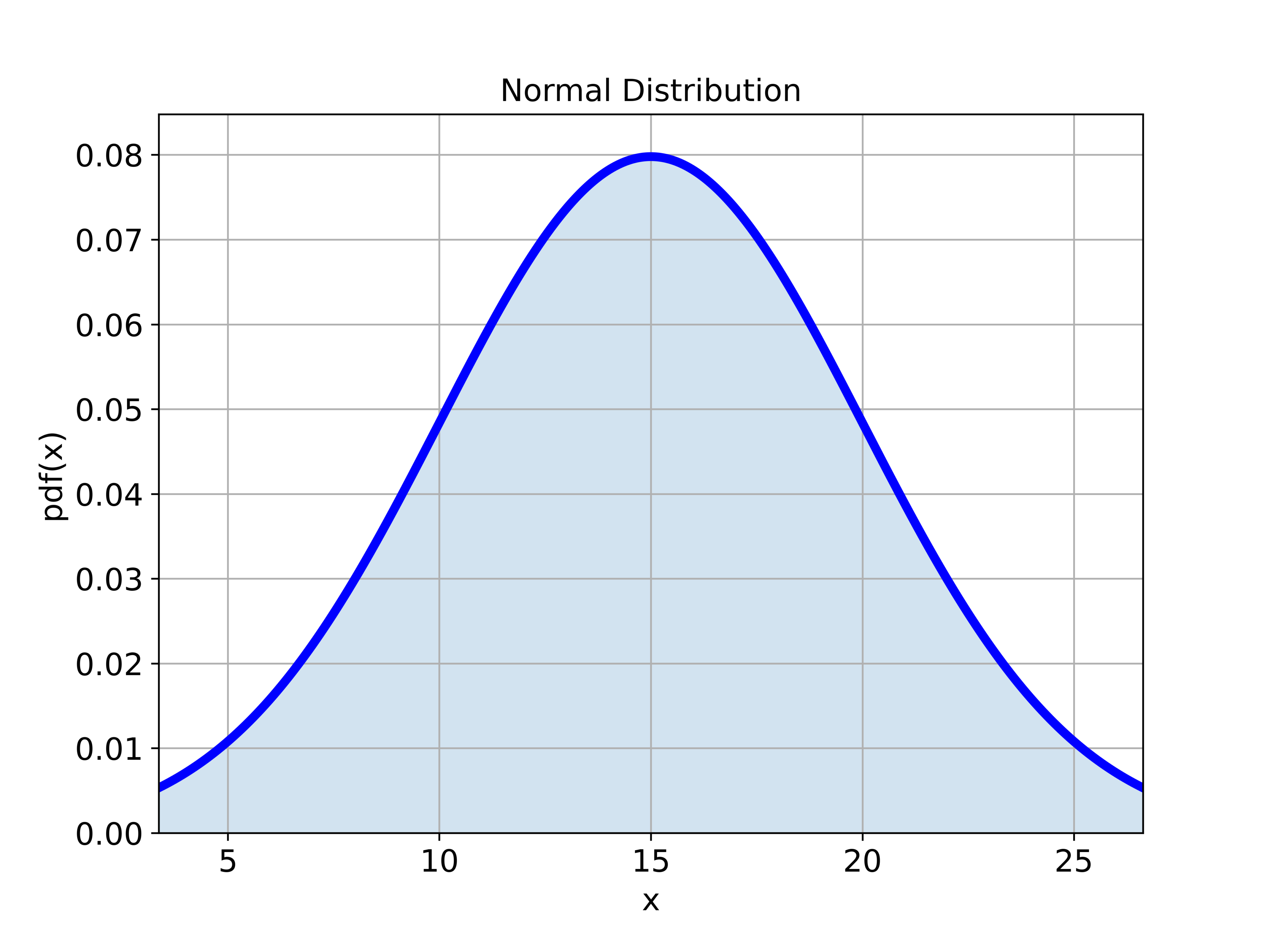
Next, let us draw samples of different sizes from this distribution, and let us compute the Monte Carlo estimator of the mean:
# generate random samples from the normal distribution and compute the mean
sampleSize1=10
randomSamples1 = distribution.rvs(size=sampleSize1)
average1=randomSamples1.mean()
sampleSize2=20
randomSamples2 = distribution.rvs(size=sampleSize2)
average2=randomSamples2.mean()
sampleSize3=40
randomSamples3 = distribution.rvs(size=sampleSize3)
average3=randomSamples3.mean()
sampleSize4=100
randomSamples4 = distribution.rvs(size=sampleSize4)
average4=randomSamples4.mean()
The true mean of the distribution is 

average1=16.15347243875767
average2=13.825483594640009
average3=14.191662810585807
average4=14.766381245499495
We can observe that as
Basic Idea of the Monte Carlo Method – Integral of Nonlinear Function of Random Variable
In the previous section, we explained how to approximate the mean of a random variable by using the Monte Carlo method. However, the Monte Carlo method can also be used to approximate integrals of nonlinear functions of random variables.
Let us consider the following integral
(4) 

where 



(5) ![\begin{align*}I=\mathbb{E}[g(X)]=\int_{a}^{b}g(x)f(x)\text{d}x\end{align*}](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-46ed48f82cd6cf7e9801b89a9cc33426_l3.png "Rendered by QuickLaTeX.com")

For the most general form of the function
The Monte Carlo method approximates the integral (4) by performing the following two steps.
- Draw
- Approximate the integral (4) by the following average:
(6)

where


It can be shown that as
Next, let us numerically verify this approximation. Let us assume that the random variable 



(7) 

Obviously, this integral is the expectation of the nonlinear function 



(8) 

where 





import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# define a normal distribution in Python:
# mean value
meanValue=10
# standard deviation
standardDeviation=5
# create a normal distribution
# the keyword "loc" is used to specify the mean
# the keyword "scale" is used to specify the standard deviation
distribution=stats.norm(loc=meanValue, scale=standardDeviation)
# plot the probability density function of the distribution
# start point
startPointXaxis=distribution.ppf(0.01)
# end point
endPointXaxis=distribution.ppf(0.99)
# create the x values
xValue = np.linspace(startPointXaxis,endPointXaxis, 500)
# the function pdf() will return the probability density function values
yValue = distribution.pdf(xValue)
# plot the probability density function
plt.figure(figsize=(8,6))
plt.gca()
plt.plot(xValue,yValue, color='blue',linewidth=4)
plt.fill_between(xValue, yValue, alpha=0.2)
plt.title('Normal Distribution', fontsize=14)
plt.xlabel('x', fontsize=14)
plt.ylabel('pdf(x)',fontsize=14)
plt.tick_params(axis='both',which='major',labelsize=14)
plt.grid(visible=True)
plt.xlim((startPointXaxis,endPointXaxis))
plt.ylim((0,max(yValue)+0.005))
plt.savefig('normalDistribution2.png',dpi=600)
plt.show()
# generate random samples from the normal distribution
# and compute the variance estimate
sampleSize1=10
randomSamples1 = distribution.rvs(size=sampleSize1)
sum1=[(x-meanValue)**2 for x in randomSamples1]
varianceEstimate1=np.array(sum1).mean()
sampleSize2=20
randomSamples2 = distribution.rvs(size=sampleSize2)
sum2=[(x-meanValue)**2 for x in randomSamples2]
varianceEstimate2=np.array(sum2).mean()
sampleSize3=40
randomSamples3 = distribution.rvs(size=sampleSize3)
sum3=[(x-meanValue)**2 for x in randomSamples3]
varianceEstimate3=np.array(sum3).mean()
sampleSize4=100
randomSamples4 = distribution.rvs(size=sampleSize4)
sum4=[(x-meanValue)**2 for x in randomSamples4]
varianceEstimate4=np.array(sum4).mean()
sampleSize5=500
randomSamples5 = distribution.rvs(size=sampleSize5)
sum5=[(x-meanValue)**2 for x in randomSamples5]
varianceEstimate5=np.array(sum5).mean()
sampleSize6=1000
randomSamples6 = distribution.rvs(size=sampleSize6)
sum6=[(x-meanValue)**2 for x in randomSamples6]
varianceEstimate6=np.array(sum6).mean()
sampleSize7=10000
randomSamples7 = distribution.rvs(size=sampleSize7)
sum7=[(x-meanValue)**2 for x in randomSamples7]
varianceEstimate7=np.array(sum7).mean()
The result is
varianceEstimate1=18.271278554682066
varianceEstimate2=25.062558928196857
varianceEstimate3=27.343302796496573
varianceEstimate4=26.441209742610326
varianceEstimate5=21.826967279955614
varianceEstimate6=26.349949141991836
varianceEstimate7=24.69480444231385Basic Idea of the Monte Carlo Method – Approximation of Deterministic Integrals
Here, we briefly explain how to use the Monte Carlo method to approximate deterministic integrals. Let us consider this integral
(9) 

where 

(10) 

where 
![[a,b]](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-fcda5ef4ae327e1afef79dc73df91703_l3.png "Rendered by QuickLaTeX.com")


(11) 

where
(12) 

and the interval ![[1,3]](https://aleksandarhaber.com/wp-content/ql-cache/quicklatex.com-b18b42edced7587049ed217292cf0269_l3.png "Rendered by QuickLaTeX.com")

(13) 

The Python script given below creates a uniform distribution and approximates the integral
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
# define a uniform distribution in Python on the interval [a,b+1]
a=1
b=2
# create a uniform distribution
distribution=stats.uniform(a, b)
# plot the probability density function of the distribution
# start point
startPointXaxis=distribution.ppf(0.01)
# end point
endPointXaxis=distribution.ppf(0.99)
# create the x values
xValue = np.linspace(startPointXaxis,endPointXaxis, 500)
# the function pdf() will return the probability density function values
yValue = distribution.pdf(xValue)
# plot the probability density function
plt.figure(figsize=(8,6))
plt.gca()
plt.plot(xValue,yValue, color='blue',linewidth=4)
plt.fill_between(xValue, yValue, alpha=0.2)
plt.title('Uniform Distribution', fontsize=14)
plt.xlabel('x', fontsize=14)
plt.ylabel('pdf(x)',fontsize=14)
plt.tick_params(axis='both',which='major',labelsize=14)
plt.grid(visible=True)
plt.xlim((startPointXaxis-0.1,endPointXaxis+0.1))
plt.ylim((0,max(yValue)+0.01))
plt.savefig('uniformDistribution2.png',dpi=600)
plt.show()
# generate random samples from the normal distribution
# and compute the variance estimate
sampleSize1=10
randomSamples1 = distribution.rvs(size=sampleSize1)
sum1=[(x)**3 for x in randomSamples1]
integralEstimate1=(b-a+1)*np.array(sum1).mean()
sampleSize2=20
randomSamples2 = distribution.rvs(size=sampleSize2)
sum2=[(x)**3 for x in randomSamples2]
integralEstimate2=(b-a+1)*np.array(sum2).mean()
sampleSize3=40
randomSamples3 = distribution.rvs(size=sampleSize3)
sum3=[(x)**3 for x in randomSamples3]
integralEstimate3=(b-a+1)*np.array(sum3).mean()
sampleSize4=100
randomSamples4 = distribution.rvs(size=sampleSize4)
sum4=[(x)**3 for x in randomSamples4]
integralEstimate4=(b-a+1)*np.array(sum4).mean()
The uniform distribution is given in the figure below.
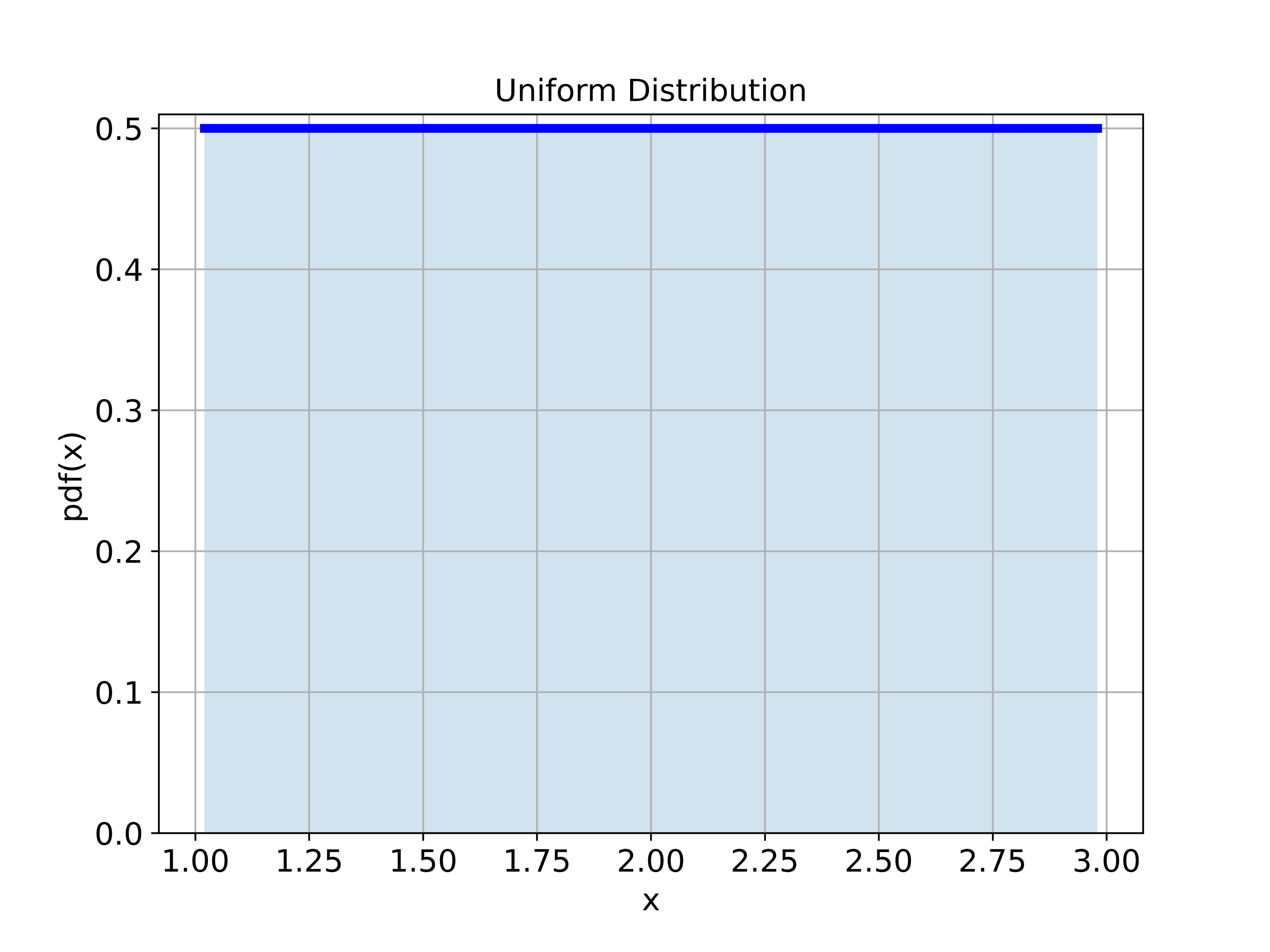
The approximation results are given below
integralEstimate1=15.01969583856625
integralEstimate2=23.308232850684064
integralEstimate3=18.154486022709897
integralEstimate4=22.051801180232648