In this post, we provide a brief introduction to Linear Quadratic Regulator (LQR) for set point control. Furthermore, we explain how to compute and simulate the LQR algorithm in MATLAB. The main motivation for developing this lecture comes from the fact that most application-oriented tutorials available online are focusing on the simplified case in which the set point is a zero state (equilibrium point). However, less attention has been dedicated to the problem of regulating the system state to non-zero set points (desired states). The purpose of this lecture and the accompanying YouTube video is to explain how to compute and simulate a general form of the LQR algorithm that works for arbitrary set points. The YouTube video accompanying this post is given below. The GitHub page with all the codes is given here.

The LQR algorithm is arguably one of the simplest optimal control algorithms. Good books for learning optimal control are:
1.) Kwakernaak, H., & Sivan, R. (1972). Linear optimal control systems (Vol. 1, p. 608). New York: Wiley-Interscience.
2.) Lewis, F. L., Vrabie, D., & Syrmos, V. L. (2012). Optimal Control. John Wiley & Sons.
3.) Anderson, B. D., & Moore, J. B. (2007). Optimal Control: Linear Quadratic Methods. Courier Corporation.
To explain the basic principles and ideas of the LQR algorithm, we use an example of a mass-spring-damper system that is introduced in our previous post, which can be found here. The sketch of the system is shown in the figure below

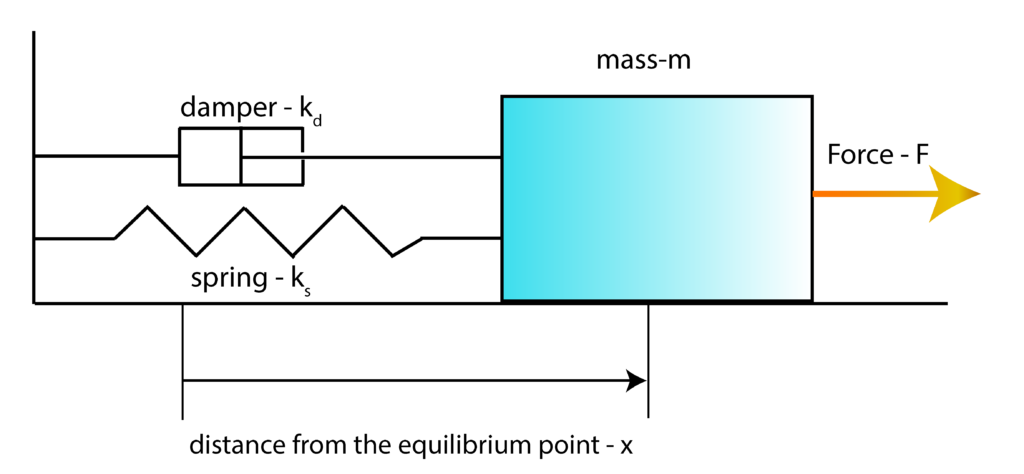
First, we introduce the state-space variables
(1) 

where 

(2) 

Since in this post, we are considering state feedback, the output equation is not relevant. However, for completeness, we will write the output equation
(3) 

In this particular post and lecture, we assume that the full state information is available at every time instant. That is, we assume that both 



The goal of the set point regulation is to steer the system to the desired state (desired set point) 

In this post, we will use the terms “desired state” and “desired set point” interchangeably. The first step is to determine the control input 





(4) 

where 



(5) 

In principle, we can control the system by applying the constant control input
To develop the control algorithm, we introduce the error variables as follows
(6) 

By differentiating these expressions and by substituting (6) in (2), we obtain
(7) 

Here it should be kept in mind that since 
(8) 

On the other hand, by substituting (4) in (8), we obtain
(9) 

Having this form of dynamics, we can straightforwardly apply the LQR algorithm that is derived under the assumption of zero desired state. The LQR algorithm optimizes the following cost function
(10) 

where





(11) 

where 





(12) 

where the matrix 
(13) 

where 

(14) 

Fortunately, we do not need to write our own code for solving the Riccati equation. We will use the MATLAB function lqr() to compute the control matrix
(15) 

The LQR control algorithm will make the matrix 



(16) 

The equation (16) can be used to simulate the closed loop system.
Taking into account the error variables (6), we can write the feedback control (12), as follows
(17) 

We now proceed with defining the system in MATLAB and with simulations.
First, using the procedure explained in our previous post, we define the system state-space representation:
clear, pack, clc
% mass
m=10
% damping
kd=5
% spring constant
ks=10
%% state-space system representation
A=[0 1; -ks/m -kd/m];
B=[0; 1/m];
C=[1 0];
D=0;
sysSS=ss(A,B,C,D)
Then, we define the desired state, and we compute the steady-state control input using (5).
%% define the desired state
xd=[3;0];
%% compute ud
ud=-inv(B'*B)*B'*A*xd
The desired state is 


%% simulate the system response for the computed ud
% set initial condition
x0=1*randn(2,1);
%final simulation time
tFinal=30;
time_total=0:0.1:tFinal;
input_ud=ud*ones(size(time_total));
[output_ud_only,time_ud_only,state_ud_only] = lsim(sysSS,input_ud,time_total,x0);
figure(1)
plot(time_total,state_ud_only(:,1),'k')
hold on
plot(time_total,state_ud_only(:,2),'r')
xlabel('Time [s]')
ylabel('Position and velocity')
legend('Position','Velocity')
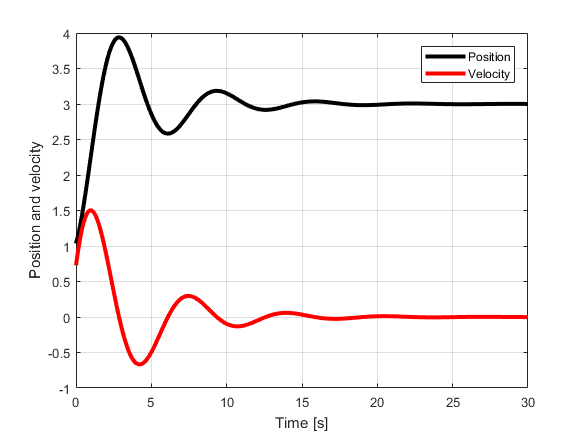
grid
The figure below shows the simulated state trajectories. The position (

The next goal is to simulate the LQR algorithm. We compute the control matrix
%% simulate the LQR algorithm
Q= 10*eye(2,2);
R= 0.1;
N= zeros(2,1);
[K,S,e] = lqr(sysSS,Q,R,N);
% compute the eigenvalues of the closed loop system
eig(A-B*K)
% eigenvalues of the open-loop system
eig(A)
%simulate the closed loop system
% closed loop matrix
Acl= A-B*K;
Bcl=-Acl;
C=[1 0];
D=0;
sysSSClosedLoop=ss(Acl,Bcl,C,D)
closed_loop_input=[xd(1)*ones(size(time_total));
xd(2)*ones(size(time_total))];
[output_closed_loop,time_closed_loop,state_closed_loop] = lsim(sysSSClosedLoop,closed_loop_input,time_total,x0);
figure(2)
plot(time_total,state_ud_only(:,1),'k')
hold on
plot(time_total,state_ud_only(:,2),'r')
xlabel('Time [s]')
ylabel('Position and velocity')
plot(time_closed_loop,state_closed_loop(:,1),'m')
hold on
plot(time_closed_loop,state_closed_loop(:,2),'b')
legend('Position-Constant Input ','Velocity-Constant Input','Position-Closed Loop ','Velocity-Closed Loop')
grid
Here, we compare the state trajectories of the closed loop system (LQR algorithm) with the state trajectories of the system for the constant steady-state input. This is done to investigate the performance gain obtained by using the LQR algorithm.

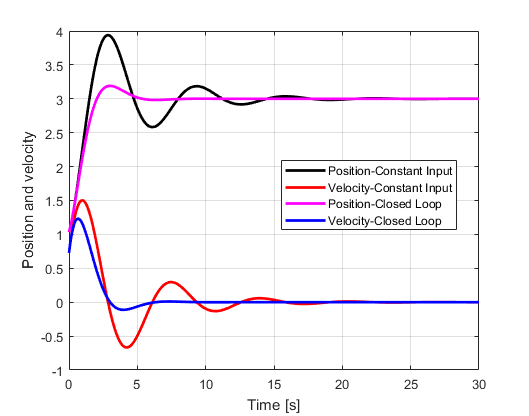
From Fig. 3., we can clearly observe the advantages of the LQR algorithm. We can observe that the overshoot is decreased and that the convergence is much faster compared to the system that is controlled using the steady-state control input. Also, the eigenvalues of the matrix A are
-0.2500 + 0.9682i
-0.2500 – 0.9682i
And the eigenvalues of the closed-loop matrix A-BK are
-0.7208 + 0.9458i
-0.7208 – 0.9458i
Since the real parts of the eigenvalues of the closed-loop matrix are almost 3 times further left in the complex plane compared to the eigenvalues of the open-loop system, we can see that the closed-loop system has much more favorable poles from the stability point of view compared to the poles of the open-loop system.